
メルカリで無作為に商品検索しても、目当ての出品物が見つからないことがあります。
またクラウドソーシングサイトの案件でも、大量の特定キーワードによる出品物一覧データ取得や有在庫/無在庫転売ツール開発に取り組むこともあります。
本記事は、以下の目的を持った人におすすめです。
|
おそらく、上記内容を目的とする人であれば様々な媒体で自動化/効率化を考えていると思います。
また、pythonによるプログラミングの目的として以下の3つがあります。
|
これらの目的を持ったプログラミング初心者であれば、本記事の内容は最適な学習内容です。
また、筆者自身クラウドソーシングサイトであるランサーズにてコンスタントに毎月10万円を稼ぎ、スクレイピング業務にて2021年6月に最高報酬額である30万円を突破しました。
年間報酬額も100万円突破するなど、実務的なスクレイピング技術の活用方法や具体的な稼ぎ方について、一定の記事信頼を担保できると思います。
プログラミングの中でもスクレイピング技術は習得することで、副業に十分活かせる武器になると先にお伝えしておきます。
目次
メルカリにおけるスクレイピングツールの概要
Pythonによるメルカリのスクレイピングツールの全体像は以下の流れです。
|
検索キーワードを軸にメルカリサイト内で商品検索を行います。
検索キーワードをきっかけにスクレイピングツールが実行されます。
最終的に、検索結果の商品一覧ページから情報を取得してCSVファイルに出力します。
次に、商品の詳細ページから取得する情報は以下の6つです。
|
商品ページでは6つ以外の情報も存在するため、必要に応じて取得データを変更してみましょう。
以降の解説の中で取得方法を記載するので、上記の情報以外で取得したいデータがあれば試してみてください。
pythonによるスクレイピングツールの仕組み
pythonを利用してスクレイピングを実行するにあたって、以下の項目を満たしていきます。
|
これらの条件を満たすためにスクレイピングプログラムを実装します。
そして、本プログラムのメインとなるのがpythonのライブラリであるSeleniumです。
Seleniumを利用することでブラウザ操作を自動化しWebスクレイピングを実現します。
スクレイピングに関して、他にもrequestsやBeautifulSoupといったライブラリも存在します。
スクレイピングに関するpythonのライブラリを詳しく知りたい人は「【python】スクレイピングで利用する各種ライブラリと稼ぐための活用方法」で解説します。

Seleniumの実行環境を構築する
はじめに、スクレイピングツールで必要となるライブラリ/モジュールをインポートします。
from selenium import webdriver import time import pandas
seleniumに関してはコマンドプロンプトあるいはターミナル等でインストールする必要があります。
pip install selenium
pipのバージョンに合わせてpip/pip3にてインストールしてください。
また、SeleniumではWebdriberを利用してブラウザ操作を行います。
そのため、https://chromedriver.chromium.org/downloadsにてWebdriverのダウンロードを適宜実施してください。
プログラム内でパス設定があるため、.pyファイルと同ディレクトリであれば比較的簡単に設定できると思います。
また、お使いのChromeのバージョンに合わせてダウンロードしてください。
timeモジュールは、サイトアクセス時の表示まで待機させるプログラムに利用します。
pandasモジュールは、取得したデータをCSVファイルに出力するために利用します。
Seleniumにてメルカリサイトへアクセス実行/確認
先にメルカリへアクセスしたブラウザ表示結果から、キーワード検索後のURLを確認します。
ここでは、キーワードとして『ゲーム』と指定します。
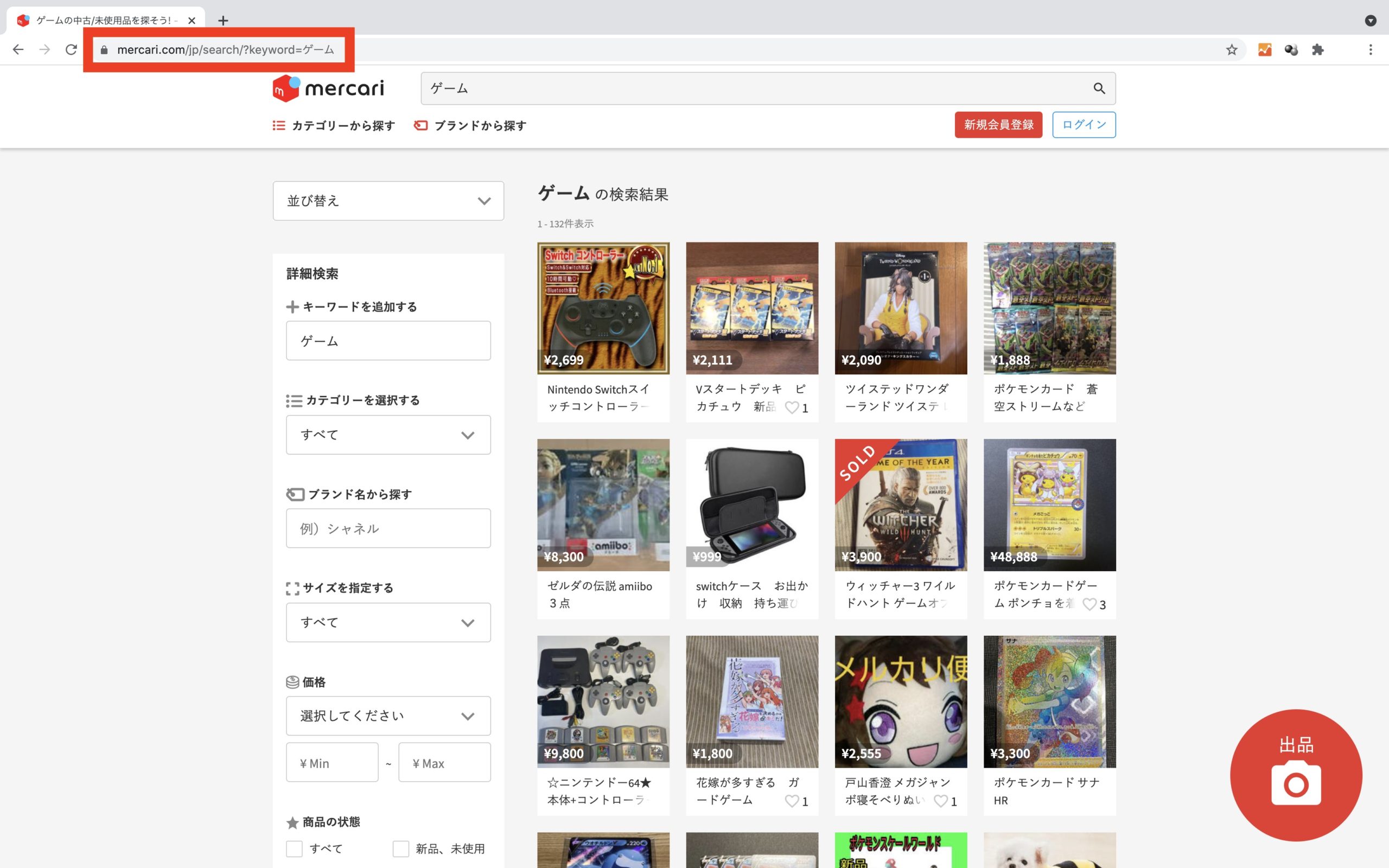
メルカリへアクセス後キーワード検索した結果、以下のURLを利用してサイトアクセスすればよいことが分かります。
https://www.mercari.com/jp/search/?keyword=ゲーム
上記のURLを利用してキーワードを入力し、キーワード検索が実行できるプログラムを実装していきます。
#キーワード入力
search_word = input("検索キーワード=")
# メルカリ
url = 'https://www.mercari.com/jp/search/?keyword=' + search_word
# chromedriverの設定とキーワード検索実行
driver = webdriver.Chrome(r"パス入力")
driver.get(url)プログラム実行後、input()関数にてsearch_word(キーワード)を決定します。
url変数では、メルカリにて検索結果が表示されるURLとsearch_wordの組み合わせを格納しています。
driver変数にてwebdriverを格納して、driver.get(url)にてメルカリサイトへアクセスしています。
メルカリの商品一覧ページから各商品ページURLを取得
次に、メルカリの商品一覧ページから各商品ページURLを取得します。
そのため、商品一覧ページから各商品ページのURLが記載されているHTML要素を確認します。
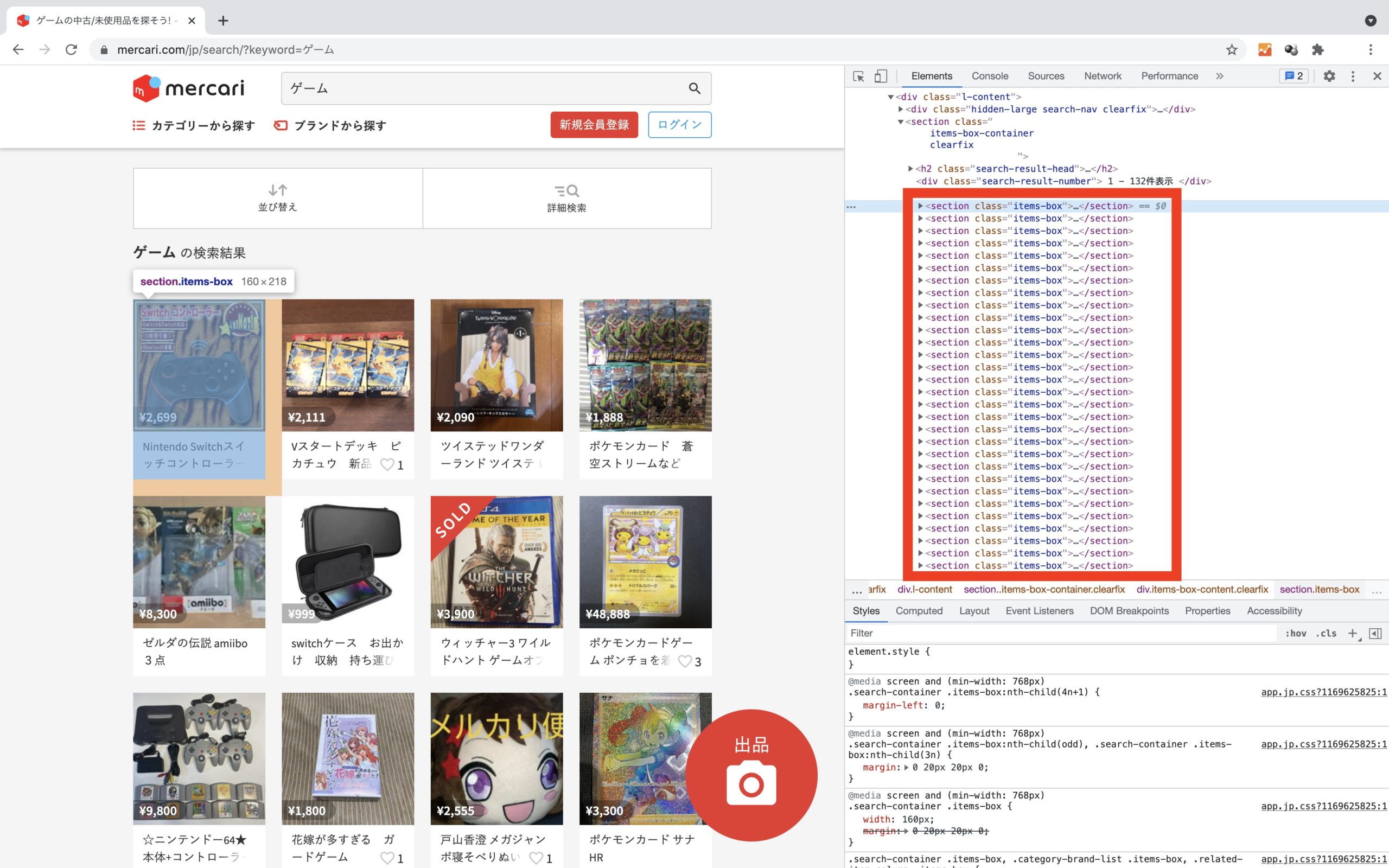
Chromeのデベロッパーツールにてメルカリのソースコードを確認すると、各商品を表示している<section>タグに格納されていることが分かります。
さらにHTML要素の<section>タグ内を確認すると、class名が”items-box”と記載されています。
class名の”items-box”を中心にスクレイピングコードを実装します。
# ページカウントとアイテムカウント用変数 page = 1 item_num = 0 item_urls = []
はじめに、検索結果である商品一覧ページの1ページ目を軸に考えます。
そのため、page変数を定義して1を格納します。
また、item_num変数を定義して取得する商品があるたびにカウントを行います。
while True:
print("Getting the page {} ...".format(page))
time.sleep(1)
items = driver.find_elements_by_class_name("items-box")
for item in items:
item_num += 1
item_url = item.find_element_by_css_selector("a").get_attribute("href")
print("item{0} url:{1}".format(item_num, item_url))
item_urls.append(item_url)
page += 1
try:
next_page = driver.find_element_by_css_selector("li.pager-next .pager-cell:nth-child(1) a").get_attribute("href")
driver.get(next_page)
print("next url:{}".format(next_page))
print("Moving to the next page...")
except:
print("Last page!")
breakwihle文を利用して最後のページまで繰り返し処理を実装します。
time.sleep(1)は、Webスクレイピングによる処理でサーバーに負担をかけないよう実装しています。
items変数へ.find_elements_by_class_name()メソッドを利用して、各商品ページを持つ”items-box”を指定しHTML要素を抽出します。
for文にてアイテムカウントを行い、商品ページURLを持つitemsのリストから1HTML要素を抜き出し、.find_elements_by_css_selector()メソッドと.get_attribute()メソッドでURLを抽出します。

抽出した各商品ページURLをitem_urlsのリスト変数へ格納します。
1ページ目の各商品ページURLが取得できたら、page変数に1を加算し2ページ目に遷移し同様の処理を繰り返します。

2ページ目に関しては、try-except文にてnext_page変数を用意し.find_elements_by_css_selector()メソッドと.get_attribute()メソッドで2ページ目のURLを取得します。
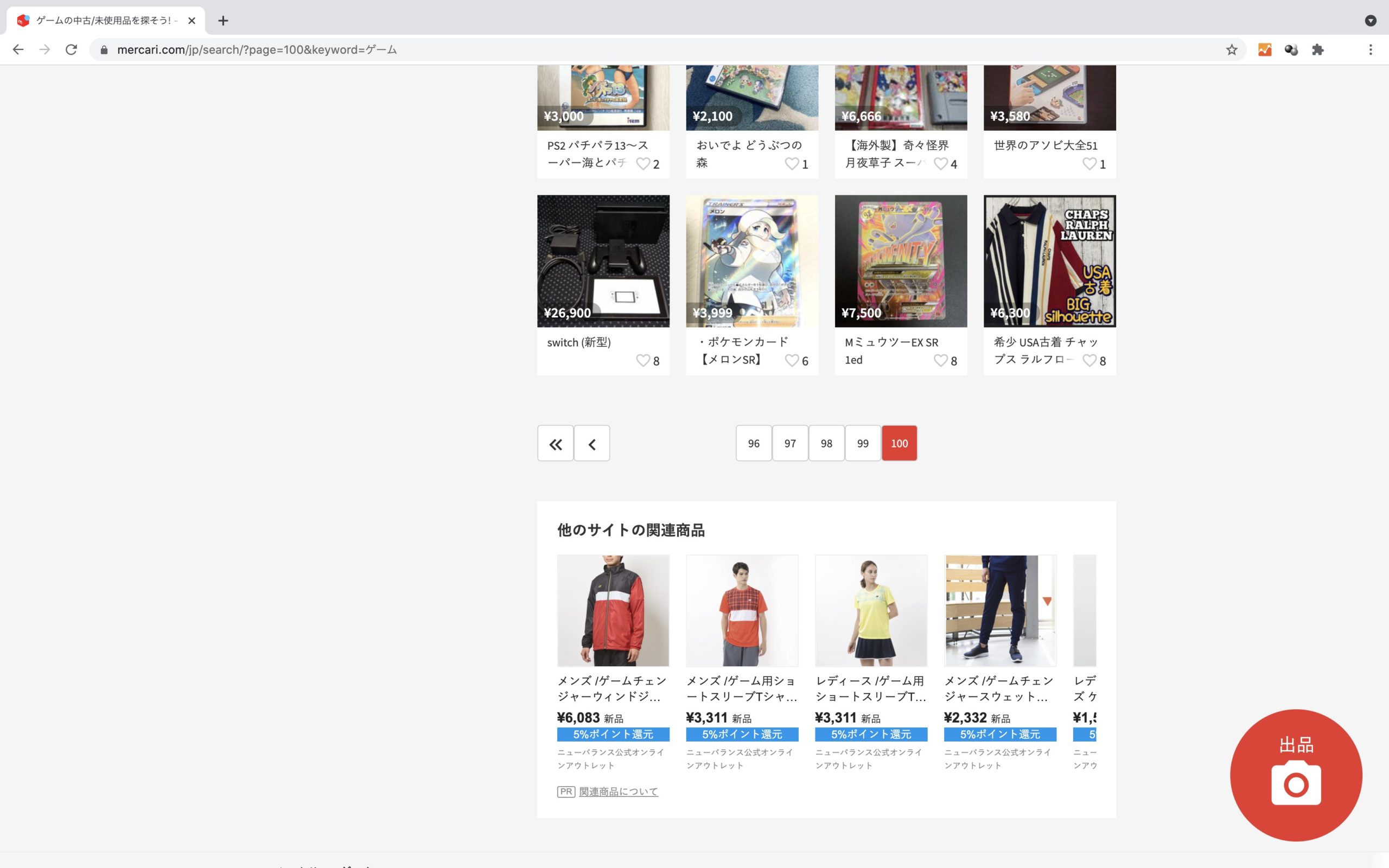
最後のページは、次ページへの遷移ボタンが存在しないためエラーとなることが分かります。
そのため、except文にてbreakを記述することでwhile文によるループ処理から抜け出します。
このwhile文で記述した一連の処理によって、各一覧ページごとの商品ページURLを全て取得します。
商品の詳細情報をCSVファイルに出力する準備
商品の詳細情報を取得し始める前に、CSVファイルへの出力準備を行います。
# CSVファイルに出力する準備 item_num = 0 columns = ["item_name", "cat1", "cat2", "cat3", "brand_name", "product_state", "price", "url"] df = pandas.DataFrame(columns=columns)
各ページの各商品をカウントしていたitem_num変数を初期化しておきます。
item_num変数を初期化しておくことで、改めて各商品を1からカウントできるように準備しています。
columns変数では、リストを用意して各リスト名を付与したデータを格納しています。
df変数では、pandasモジュールを利用しDataFrame()メソッドにて、columns変数を引数に渡しています。
取得した各商品ページURLへアクセスし詳細情報を取得
いよいよ取得した各商品ページURLへアクセスしますが、商品ページの詳細情報がどのようなHTML要素で記載されているかでベロッパーツールで確認します。
|
これらを順に、メルカリの商品ページにてHTML要素を確認します。
商品名
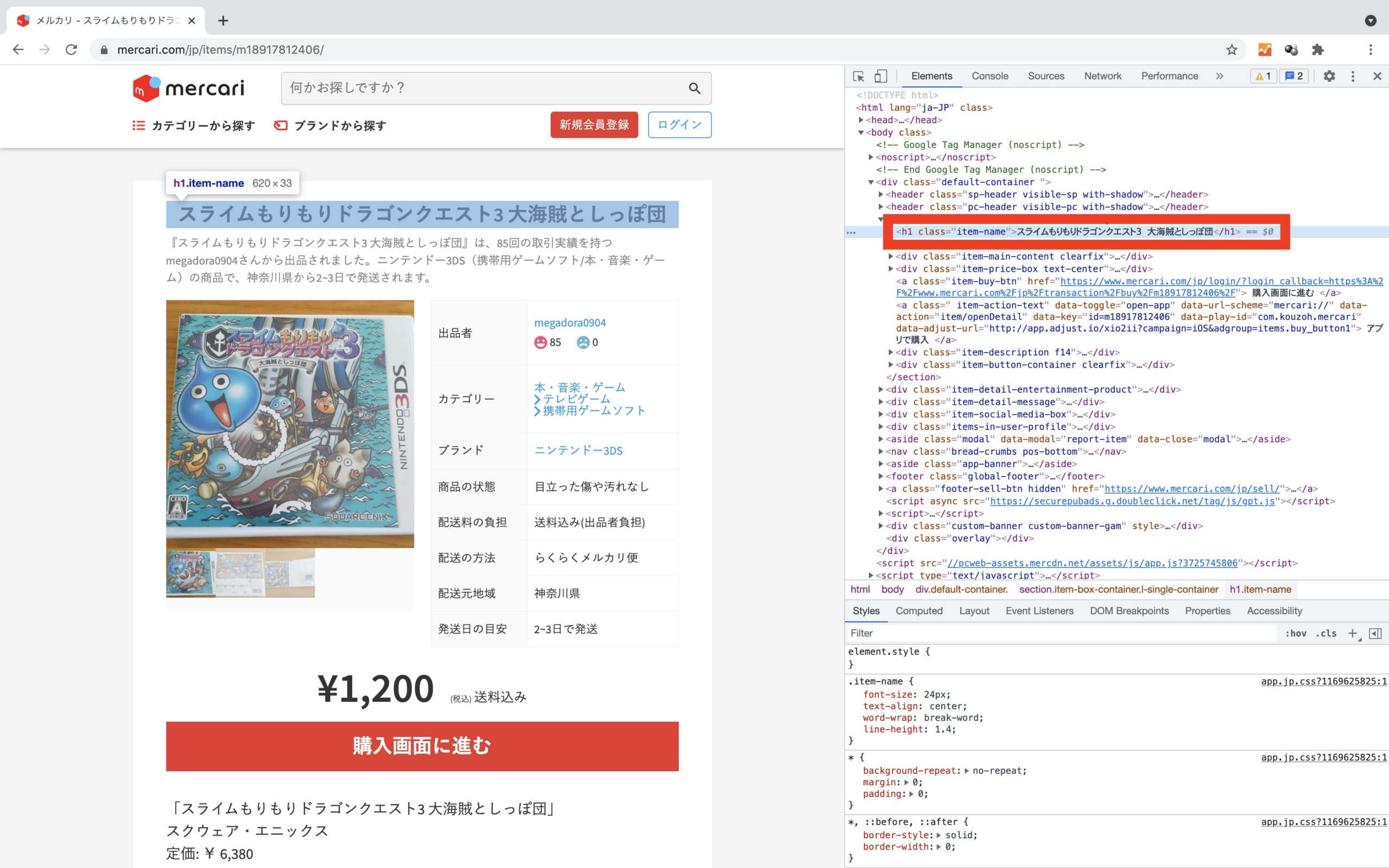
Chromeのデベロッパーツールで確認すると、<h1>タグのclass名”items-name”に商品名のテキストが存在しています。
item_name = driver.find_element_by_css_selector("h1.item-name").textitem_name変数を用意して、.find_element_by_css_selector()メソッドにてCSS要素を指定することでテキストを抽出/格納します。
商品カテゴリー
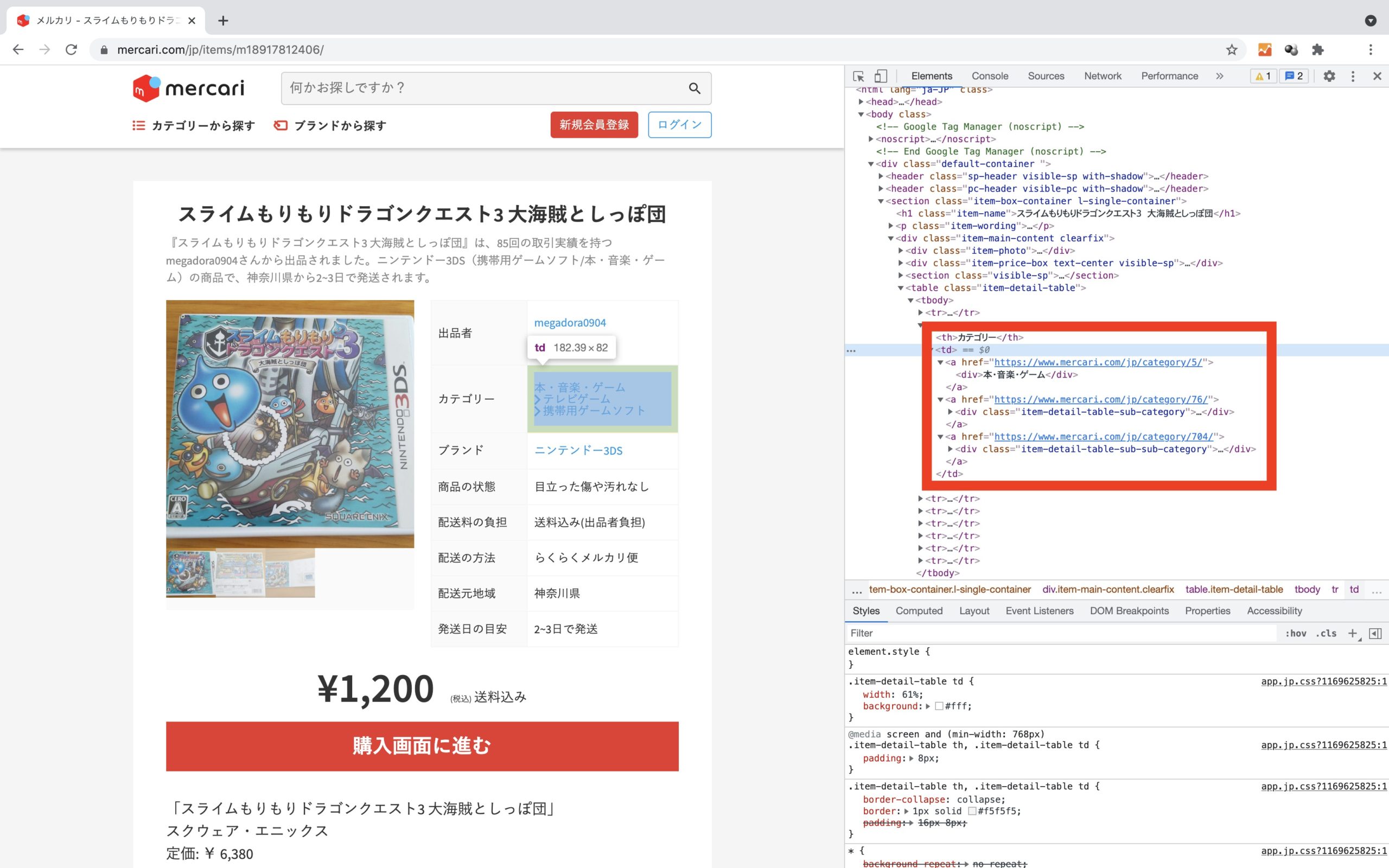
Chromeのでデベロッパーツールで確認すると、<td>タグの中にカテゴリーのテキストが存在しています。
cat1 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(1) div").text
cat2 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(2) div").text
cat3 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(3) div").textcat1, cat2, cat3変数を用意して、.find_element_by_css_selector()メソッドにてCSS要素を指定することでテキストを抽出/格納します。
ブランド名
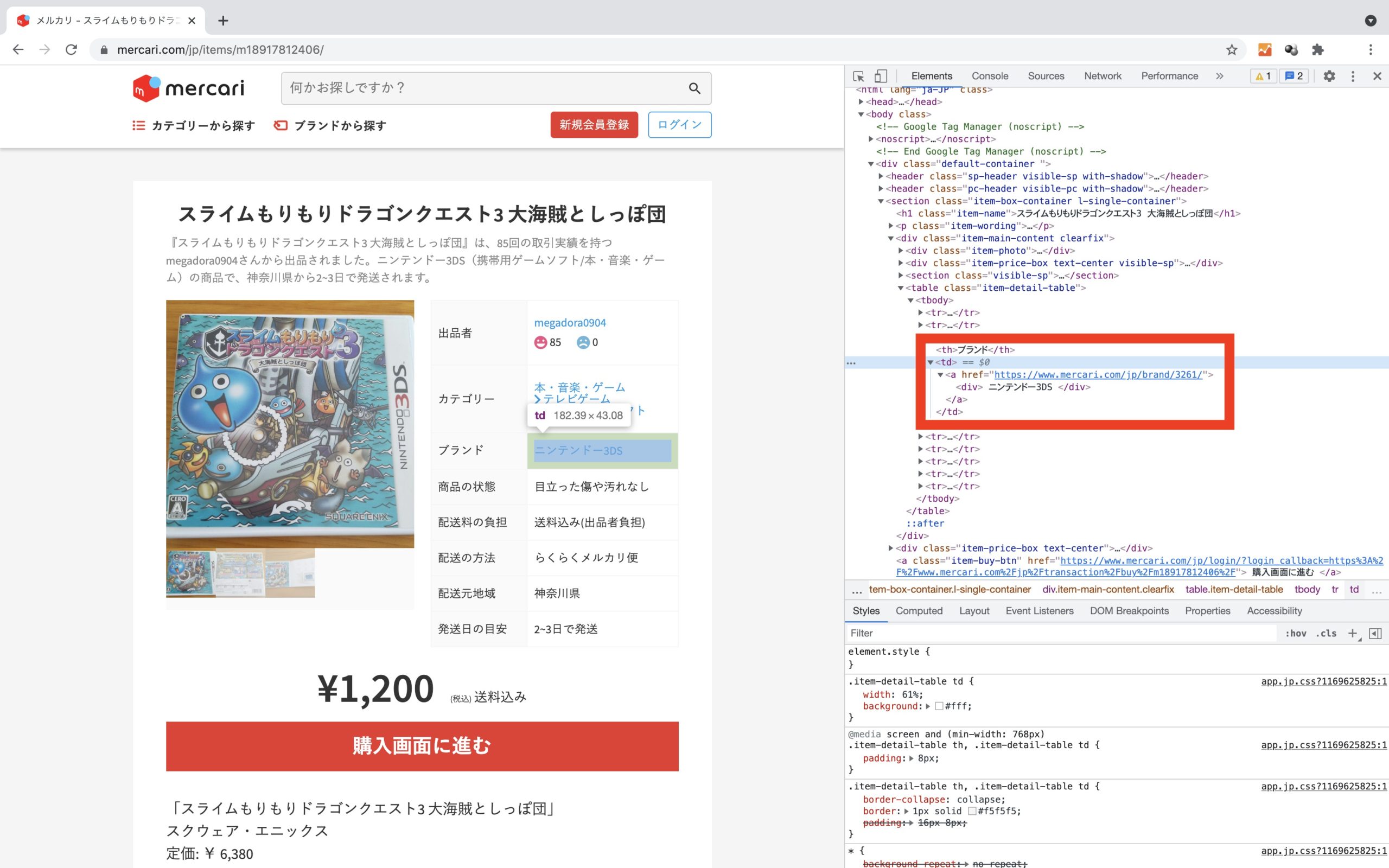
Chromeのでデベロッパーツールで確認すると、<td>タグの中にブランドのテキストが存在しています。
brand_name = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(3) td a div").textbrand_name変数を用意して、.find_element_by_css_selector()メソッドにてCSS要素を指定することでテキストを抽出/格納します。
商品状態
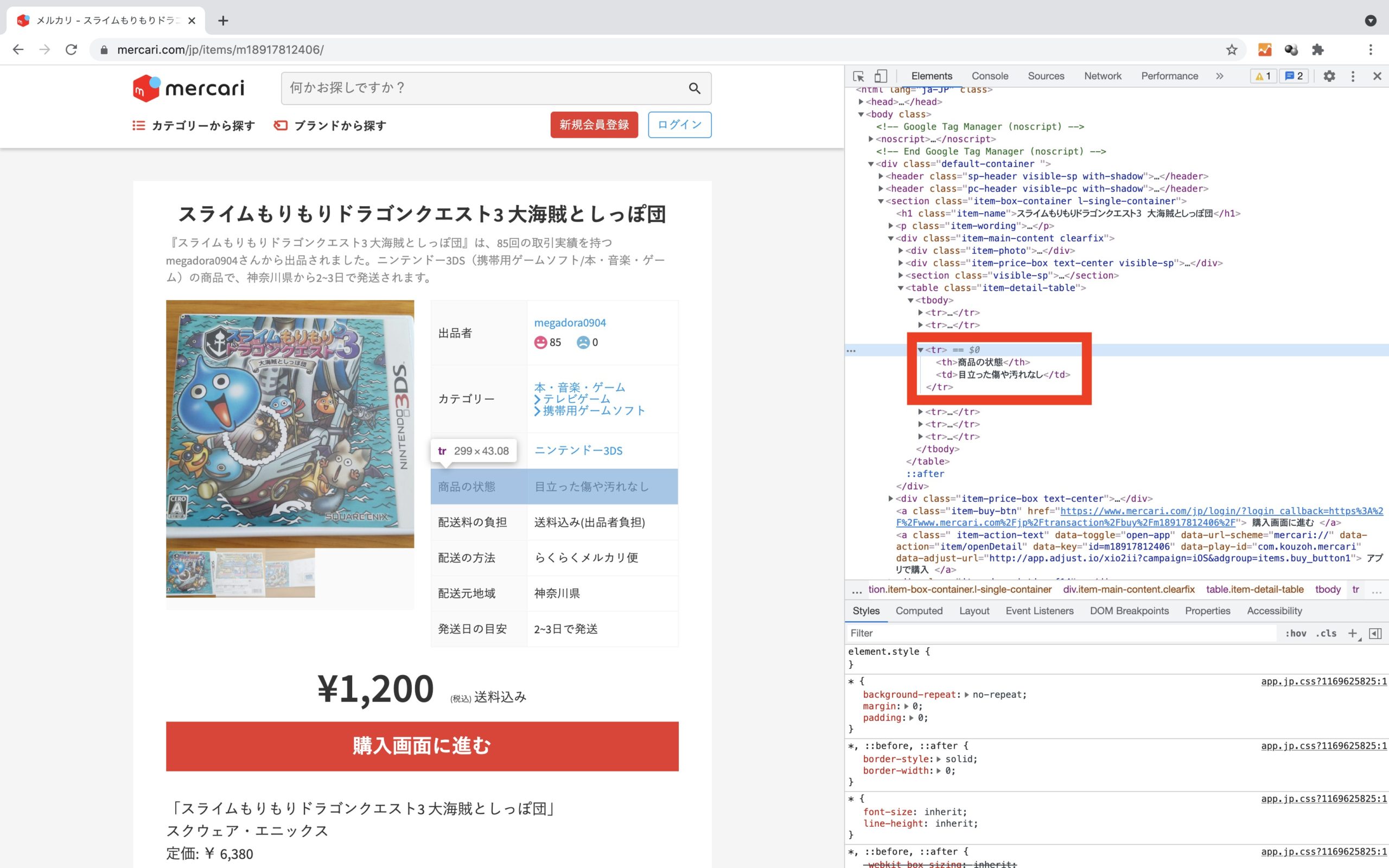
Chromeのでデベロッパーツールで確認すると、<td>タグの中に商品状態のテキストが存在しています。
product_state = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(4) td").textproduct_state変数を用意して、.find_element_by_css_selector()メソッドにてCSS要素を指定することでテキストを抽出/格納します。
金額

Chromeのでデベロッパーツールで確認すると、<span>タグのclass名”item-price bold”に金額のテキストが存在しています。
price = driver.find_element_by_xpath("//div[1]/section/div[2]/span[1]").text
price = price.replace("¥", "").replace(" ","").replace(",", "")price変数を用意して、.find_element_by_xpath()メソッドにてxpathを指定することでテキストを抽出/格納します。
また、replace()メソッドを利用して数字の文字列へ変換しています。
商品ページのURLに関しては、すでに取得しているためproduct_urlを利用します。
詳細情報取得のスクレイピングコード
取得した各商品ページURLへアクセスし詳細情報を取得するスクレイピングコードの全体像です。
try: # エラーで途中終了時をtry~exceptで対応
# 取得した全URLを回す
for product_url in item_urls:
item_num += 1
print("Moving to the item {}...".format(item_num))
time.sleep(1)
driver.get(product_url)
item_name = driver.find_element_by_css_selector("h1.item-name").text
print("Getting the information of {}...".format(item_name))
cat1 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(1) div").text
cat2 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(2) div").text
cat3 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(3) div").text
try: # 存在しない⇒a, divタグがない場合をtry~exceptで対応
brand_name = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(3) td a div").text
except:
brand_name = ""
product_state = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(4) td").text
price = driver.find_element_by_xpath("//div[1]/section/div[2]/span[1]").text
price = price.replace("¥", "").replace(" ","").replace(",", "")
print(cat1)
print(cat2)
print(cat3)
print(brand_name)
print(product_state)
print(price)
print(product_url)
se = pandas.Series([item_name, cat1, cat2, cat3, brand_name, product_state, price, product_url], columns)
df = df.append(se, ignore_index=True)
print("Item {} added!".format(item_num))
except:
print("Error occurred! Process cancelled but the added items will be exported to .csv")tr-except文にてプログラムの途中終了がある場合でも、CSVファイルにエクスポートするよう記述しています。(CSVファイルへエクスポートするコードは後述)
|
1〜6の詳細情報を取得したのち、print()メソッドにて現在のスクレイピング状況を出力しています。
se変数では、pandasのSeriesオブジェクトを生成し引数としてcolumnsを指定します。
DataFrameを持つdf変数では、se変数に格納されている各詳細情報(リスト型データ)をappend()メソッドにて追加しています。
詳細情報をCSVファイルへエクスポート
最後に、商品ページから取得した各詳細情報をCSVファイルへエクスポートします。
df.to_csv("{}.csv".format(search_word), index=False, encoding="utf_8")
driver.quit()
print("Scraping is complete!")df変数はpandas.DataFrame()メソッド作成したリストデータが格納されているため、.to_csv()メソッドを利用してCSVファイルを作成/エクスポートできます。
encodingの指定は”utf-8”にしていますが、windowsで日本語を扱う人はencoding=”cp932”のように適宜設定してください。
最後に、print()メソッドにてスクレイピング完了のテキストを出力しています。
メルカリにおけるスクレイピングツールのサンプルコード:全体像
以下のサンプルコードがメルカリにおけるスクレイピングツールの全体像になります。
from selenium import webdriver
import time
import pandas
#キーワード入力
search_word = input("検索キーワード=")
# メルカリ
url = 'https://www.mercari.com/jp/search/?keyword=' + search_word
# chromedriverの設定とキーワード検索実行
driver = webdriver.Chrome(r"パス入力")
driver.get(url)
# ページカウントとアイテムカウント用変数
page = 1
item_num = 0
item_urls = []
while True:
print("Getting the page {} ...".format(page))
time.sleep(1)
items = driver.find_elements_by_class_name("items-box")
for item in items:
item_num += 1
item_url = item.find_element_by_css_selector("a").get_attribute("href")
print("item{0} url:{1}".format(item_num, item_url))
item_urls.append(item_url)
page += 1
try:
next_page = driver.find_element_by_css_selector("li.pager-next .pager-cell:nth-child(1) a").get_attribute("href")
driver.get(next_page)
print("next url:{}".format(next_page))
print("Moving to the next page...")
except:
print("Last page!")
break
# アイテムカウントリセットとデータフレームセット
item_num = 0
columns = ["item_name", "cat1", "cat2", "cat3", "brand_name", "product_state", "price", "url"]
df = pandas.DataFrame(columns=columns)
try: # エラーで途中終了時をtry~exceptで対応
# 取得した全URLを回す
for product_url in item_urls:
item_num += 1
print("Moving to the item {}...".format(item_num))
time.sleep(1)
driver.get(product_url)
item_name = driver.find_element_by_css_selector("h1.item-name").text
print("Getting the information of {}...".format(item_name))
cat1 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(1) div").text
cat2 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(2) div").text
cat3 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(3) div").text
try: # 存在しない⇒a, divタグがない場合をtry~exceptで対応
brand_name = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(3) td a div").text
except:
brand_name = ""
product_state = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(4) td").text
price = driver.find_element_by_xpath("//div[1]/section/div[2]/span[1]").text
price = price.replace("¥", "").replace(" ","").replace(",", "")
print(cat1)
print(cat2)
print(cat3)
print(brand_name)
print(product_state)
print(price)
print(product_url)
se = pandas.Series([item_name, cat1, cat2, cat3, brand_name, product_state, price, product_url], columns)
df = df.append(se, ignore_index=True)
print("Item {} added!".format(item_num))
except:
print("Error occurred! Process cancelled but the added items will be exported to .csv")
df.to_csv("{}.csv".format(search_word), index=False, encoding="utf_8")
driver.quit()
print("Scraping is complete!")上記のサンプルコードを使用する場合、任意で.pyファイルを作成し適宜ファイル名を付け保存してください。
メルカリのスクレイピングツールの実行結果を以下の章で記載します。
また、pythonをまだインストールしていない人は「【Python初心者入門】ダウンロードとインストール方法を解説!」で解説します。

メルカリスクレイピングツールの実行結果
以下の画像は、検索キーワードとして『python 本 スクレイピング』を指定した結果になります。

2021/08/03時点で『python 本 スクレイピング』の検索結果は891件でした。
画像の通り、商品名・カテゴリー・ブランド名・商品状態・金額・URLを取得することができました。
必要に応じて、メルカリの検索詳細条件を付与したスクレイピングツールとして改善するのもありだと思います。
金額による相場価格などを割り出し、データの可視化/グラフ化してみるのも面白そうです。
まとめ
基本的なスクレイピングツールの仕組みは以下の項目を満たします。
|
これらの条件を満たすためにスクレイピングプログラムを実装します。
特に、スクレイピング技術で利用されるrequests、BeautifulSoup、Seleniumは理解しておくと作成が簡単です。
今後は、SOLD OUTとそうでないもので取得し売れ行きの良い金額データのグラフ化や簡易的なスクレイピングアプリに挑戦する予定です。
スクレイピングのライブラリや実践的なSeleniumの活用方法を知りたい人は「【python】スクレイピングで利用する各種ライブラリと稼ぐための活用方法」で解説します。
また、python初心者で作りたいものを探している人は「【認定ランサー】Python初心者が作れるものを目的別に学習方法解説!」も参考にしてみてください。

























