これまで本ブログでは、何度かPythonのテキストマイニングによる文字列の解析について扱ってきました。
具体的にはテキストデータを単語ごとに分かち書きしたり、単語ごとの品詞や出現頻度などを解析したりしてきました。
これらを押さえておけば、実際にテキストマイニングを使ってみることはもうできるはずです。
ここでもう一度おさらいすると、テキストマイニンングとはテキストデータを解析することでそれに含まれる単語を分かち書きしたり、そうして判別された単語の出現頻度や品詞などのデータを解析したりすることでした。
この記事ではテキストマイニングが実際にどのようなアプリケーションに利用されているのかというお話をいくつかさせていただき、またその一例としてWordCloudというライブラリを使って実際にコードを動かしてみたいと思います。
本ブログでも出てきたことがありますが、みなさんはこのような画像を見たことがあるのではないでしょうか?
実は、これもテキストマイニングの形態素解析が使われている一例なのです!
あとで実際にやってみますのでお楽しみに!
また、pythonをこれから本格的に学習する人は、目的を持って学習する必要があります。
こちらでは、3ヶ月間を利用して基礎学習から稼ぐまでの学習ロードマップをまとめてみましたので、本記事と合わせて一読して頂けたら幸いです。
更に実践的な稼ぎ方についてはこちらの記事をご参照ください。
Pythonのテキストマイニングで学習する対話型AI

pythonのテキストマイニングを利用する際に、様々な学習内容が存在していますが、皆さんは具体的にどのようなものをご存知でしょうか。
多くの方は、テキストマイニングを身近に感じたことがないかもしれませんが、実は利用されている場面に幾度も遭遇しています。
それらも踏まえて、お話していきます。
Pythonのテキストマイニングで文章の意味を読み解く
みなさんもよくご存知のSiriなどを筆頭とした対話型AIには、実はPythonのテキストマイニングによる形態素解析が使われています。
そもそもの話ですが、なぜSiriは人間のように言葉を認識できるのでしょうか?
ここでは音声認識の話は別のものとすることにします。あくまで、なぜAIが文章を読み取り、それに含まれた意味を認識して反応を返すということができるのか、についての話です。
文章から意味を読み取るには、それに含まれる単語同士の関係を理解しなければなりません。しかしコンピュータは通常だと、文字列を全て繋がったまま認識します。
特に日本語は品詞ごとに文字列が分かれていないので、その問題が特に顕著です。次の例を見てください。
「私はPythonを学ぶ」 → 文字列全体をひとつのつながりとして認識するので意味不明
「私」「は」「Python」「を」「学ぶ」 → 私(名詞)が Python(名詞)を 学ぶ(動詞)、と理解できる!
私たちは無意識のうちに日本語に含まれた単語を分けてそれぞれの品詞の意味を読み取ることができますが、コンピュータはそうはいきません。
そのままでは入力された文字列は、全て結合された形で認識します。
上の文章はそのままでは名詞と動詞を判別できないため、コンピュータは読めません。単語ごとに分かち書きすることで、初めて文章の主体(私)がPython(目的)を学ぶ(動詞)、と認識できます。
Pythonのテキストマイニングには日本語の形態素解析をしてくれるライブラリがある
そこで役に立つのが形態素解析です。
Pythonで利用できるJanomeのようなライブラリは、日本語の分かち書きをする機能を提供しています。
どういう仕組みかというと、Janomeは日本語でよく使われる単語があらかじめ大量に記録されている辞書のようなものを持っていて、入力された文章の中からそれに該当するものがあるかどうか、ひとつひとつ確認していくのです。
分かち書きをするだけでなく、単語ひとつひとつがどの品詞に分類されるかという解析まで行ってくれるので、これによってコンピュータは単語間の関係を認識することができます。
ちなみに英語はもともと単語ごとに分かれているので、分かち書きの必要がありません。言語の違いによってもテキストマイニングの方法論は異なるわけですね。
WordCloudはPythonのテキストマイニングで作られている

WordCloudと呼ばれるモジュールがpythonで利用することができます。
そのため、テキストマイニングで利用することを目的として、お話していきます。
Pythonのテキストマイニングで単語の出現頻度を可視化する
冒頭でも触れましたが、WordCroudはPythonのテキストマイニングで作られています。
WordCloudを知らない方のために軽く説明すると、ある文章の中の単語の出現頻度を可視化したグラフィックアートのような画像やそれを作成する機能を提供するライブラリのことです。
Twitterのつぶやきに含まれた単語で埋め尽くされたような画像を、SNSなどで見たことがある人は多いと思います。
もうお気付きの方も多いと思いますが、単語の出現頻度を調べるために形態素解析が使われています。
こういった機能もWordCloudは提供しています。
入力された文章をまず分かち書きし、そこに含まれる単語を集計。
そして出現頻度の多い単語ほど大きく描画することで、WordCloudを作成することができます。
WordCloudではWeb上の大量のデータから、ある事柄の議論でよく出てくるキーワードであったり、SNSであればそのユーザーの価値観や大事にしていることが見えてきたりするのが興味深いですね。
生のデータだけでも傾向はわかりますが、こうして画像で可視化するとより直感的になり、多くの人に伝わります。
こうしてみると、Pythonのテキストマイニングは様々なサービスに応用できそうですね。
PythonのテキストマイニングでWordCloudを作ってみよう
それでは早速PythonのテキストマイニングでWordCloudを作って見ましょう。
今回は記事のタイトルにもありますように、Appleの創業者であるスティーブ・ジョブズのスタンフォード大学におけるスピーチの原文でWordCroudを作成したいと思います。
ジョブズといえば素晴らしい起業家であると同時に、プレゼンテーションやスピーチが天才的に上手いことでも有名です。
IOTやAIなどのコンピューター技術の革新が繰り返されるこれからの時代を生き抜くためにも、勉強のついでにコンピューター革命の時代を生き抜いたジョブズの人生観について再確認してみるのも面白いと思います。
スピーチの原文は以下のサイトのものをお借りしました。
またスタンフォード大学でのジョブズのスピーチは3つのパートに分かれているため、今回はその3つそれぞれに対するWordCloudを作成して比較してみることにしてみました。
まずターミナルでWordCroudをインストールしましょう。
以下のコマンドはMacのPython3の場合です。
pip3 install WordCroud
ここからがコーディングになります。インストールしたWordCloudをimportしていきます。
from wordcloud import WordCloud
今回はスピーチの原文をテキストファイルの形で用意し、それをプログラムに読み込ませることにします。
speech.txtというファイルに先ほど貼ったサイトから英文をコピーして、Pythonファイルと同じディレクトリに置いておきましょう。
text_file = open("speech.txt")
bindata = text_file.read()
txt = bindata
WordCloudオブジェクトを生成してパラメータを入力していきます。
パラメータは左から順番に、①背景色、②フォントファイルのパス、③生成する画像の横幅、④生成する画像の縦幅です。
今回では背景色は白、HelveticaNeueフォント、横幅800、縦幅600で設定してあります。
またWindowsの場合はフォントの設定は不要なので抜かしてください。
環境にもよりますが、Macであればサンプルにあるように”System/Library/Fonts”の配下にフォントファイルがあるはずなので好きなものを選んでください。
wordcloud = WordCloud(background_color="white",
font_path="System/Library/Fonts/HelveticaNeue.ttc",
width=800,height=600).generate(txt)
最後にto_fileメソッドで画像ファイルを生成して完成です!
任意の画像ファイル名を設定してください。
wordcloud.to_file("./wordcloud_sample.png")
以下にコード全体を記載しておきます。
# coding: utf-8
from wordcloud import WordCloud
text_file = open("speech.txt")
bindata = text_file.read()
txt = bindata
wordcloud = WordCloud(background_color="white",
font_path="System/Library/Fonts/HelveticaNeue.ttc",
width=800,height=600).generate(txt)
wordcloud.to_file("./wordcloud_sample.png")
それでは作成したWordCloudを見ていきましょう。
Pythonのテキストマイニングでジョブズのスピーチを解析しよう
今回題材としたジョブズのスピーチは、以下の3つのパートに分かれています。
・connecting the dots(点と点を繋げ)
・love and loss(愛と敗北)
・death(死)
”connecting the dots”ではジョブズの生い立ちの話から始まり、Appleでコンピュータの革命を起こすまでの話とその上で重要だった考え方について触れています。
”love and loss”ではAppleを解雇され、それでも再びビジネスを始めて愛すべき妻と出会った話をしています。最後の”death”では彼の死についての考え方を述べています。
このそれぞれに相当する英文を解析し、3つのWordCloudを作成しました。
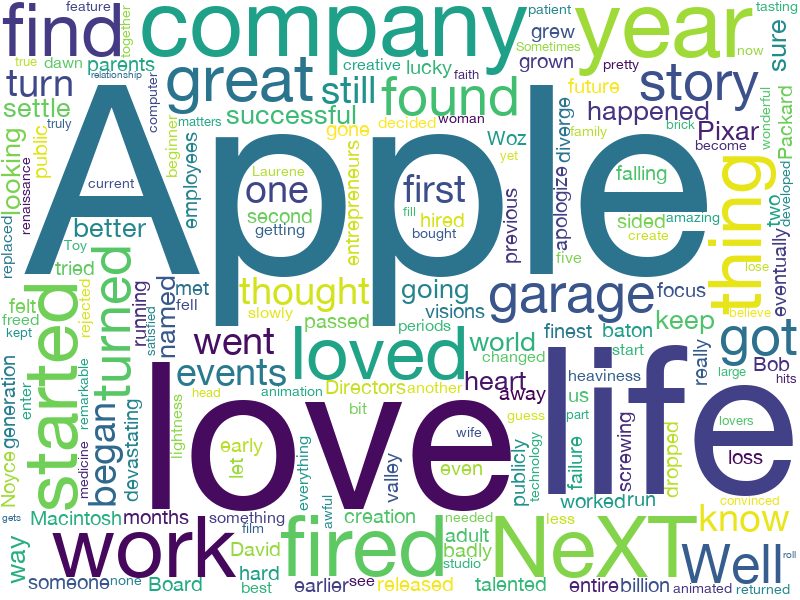
まず一つ目の”connecting the dots”から見てみましょう。
彼の生い立ちの話なのでcollege(大学)という単語が目立っていますね。
またdropped(退学)という動詞も目立ちます。
これらの単語は繰り返し使われているということですね。右上にparents(親)という単語も見えます。
これだけみてもジョブズの生い立ちの文章を解析しているということがなんとなくわかりますね。
collegeの上に重要なキーワードであるdotsがあるのも注目です。
それでは次の”love and loss”も見てみましょう。
一番目立つのはやはりAppleですね。
あとは彼がAppleを辞めた後に携わったNeXTやPixrがあることに注目。
Loveという単語の大きさも際立っています。
これは彼がこのパートで、仕事を愛することの重要性を繰り返し説いていたということですね。
それでは最後の”death”です。
death(死)やlife(人生)について繰り返し語っていたことがよく分かります。
またcancer(癌)が小さく見えることにも注目。
ここでは彼が悪性の癌と診断を受けた後に回復した話をしていました。
そして最も特筆すべきなのはStayではないでしょうか?
あの有名な”Stay Hungry. Stay Foolish. ”で出てくるからですね。
また、今後もプログラミングに取り組み続けていく中で、実務に利用できる学びを身につけていかなければなりません。
実務の中のヒントを導き出してくれるテキストマイニングという技術を習得できたおすすめのPython本が以下のものになります。
・Pythonによるテキストマイニング入門
・やってみよう テキストマイニング -自由回答アンケートの分析に挑戦!-
・言語研究のためのプログラミング入門: Pythonを活用したテキスト処理
リンク
リンク
リンク
プログラミング学習で作りたいものがない場合
独学・未経験から始める人も少なくないので、プログラミング学習の継続や学習を続けたスキルアップにはそれなりのハードルが設けられています。
また、プログラミング学習においても、学習者によってはすでに学習対象とするプログラミング言語や狙っている分野が存在するかもしれません。
そのため、費用を抑えて効率的にピンポイント学習で取り組みたいと考える人も少なくありません。
また、プログラミング学習において目的を持って取り組むことは大切ですが、『何を作ればいいかわからない。。』といったスタートの切り方で悩む人もいると思います。
そういったプログラミング学習の指標となる取り組み方について詳細に記載したまとめ記事がありますので、そちらも参照して頂けると幸いです。
Pythonに特化した学習を進めたい人へ
筆者自身は、Pythonista(Python専門エンジニア)としてプログラミング言語Pythonを利用していますが、これには取り組む理由があります。
プログラミングの世界では、IT業界に深く関わる技術的トレンドがあります。
日夜新しい製品・サービスが開発されていく中で、需要のあるプログラミング言語を扱わなければなりません。
トレンドに合わせた学習がプログラミングにおいても重要となるため、使われることのないプログラミング言語を学習しても意味がありません。
こういった点から、トレンド・年収面・需要・将来性などを含め、プログラミング言語Pythonは学習対象としておすすめとなります。
オンラインPython学習サービス – 『PyQ™(パイキュー)』

「PyQ™」は、プログラミング初心者にも優しく、また実務的なプログラミングを段階的に学べることを目指し、開発されたオンラインPython学習サービスです。
Pythonにおける書籍の監修やPythonプロフェッショナルによるサポートもあり、内容は充実しています。
技術書1冊分(3000円相当)の価格で、1ヶ月まるまるプログラミング言語Pythonを学習することができます。
特に、、、
・プログラミングをはじめて学びたい未経験者
・本、動画、他のオンライン学習システムで学習することに挫折したプログラミング初心者
・エンジニアを目指している方(特にPythonエンジニア)
かなり充実したコンテンツと環境構築不要なため、今すぐにでも学び始めたい・学び直したい、Pythonエンジニアを目指したい人におすすめです。
まとめ
いかがだったでしょうか?
同じ今回は英語で作成したのでシンプルなコードで済みましたが、日本語で作成する場合は分かち書きの必要があるのでJanomeなどのライブラリも必要となります。
英語の場合は今回の方法で作成可能なので、みなさんも好きな文章でWordCloudを作ってみてください!
TwitterなどのSNSの文章などで作成する場合は、Webスクレイピングの技術なども入ってきます。
WordCloudはPythonの様々な技術と組み合わせて応用が可能なので、気になった方は本ブログの他の記事もぜひ読んで見てくださいね。
それではここまで読んでいただきありがとうございました。