
Python初心者としてプログラミングを始めたばかりの人は、目的に合わせたPythonの使い方を理解していません。
筆者の場合、プログラミング言語Pythonを利用して5年以上も実務で活用したからこそ、蓄えられてきた知見と経験があります。
本記事は、Python初心者が作れるものを目的別に解説しながら学習方法を掲載します。
読み終えると、Pythonで何ができるか、何から始めるべきか、活用事例や副業への取り組み方も理解できます。
結論として、Python初心者(プログラミング未経験)が作れるものは限定されます。
また、筆者自身クラウドソーシングサイトであるランサーズにてコンスタントに毎月10万円を稼ぎ、プログラミング業務にて2021年6月に最高報酬額である30万円を突破しました。
年間報酬額も100万円突破するなど、実務的なプログラミングの活用方法や具体的な稼ぎ方について、一定の記事信頼を担保できると思います。
プログラミングは習得することで、本業/副業に十分活かせる武器になると先にお伝えしておきます。
目次
- 1 Python初心者が作れるもの
- 2 Pythonによるスクレイピング
- 3 Pythonによるクローリング
- 4 PythonによるExcel(エクセル)自動化
- 5 Pythonによる顔認識や物体検知
- 6 PythonによるWeb API連携
- 7 Python初心者が最初に作る簡単なプログラム【Webアプリ編】
- 8 就職支援実績あり!おすすめオンラインプログラミングスクール
- 9 Python初心者はアプリケーション開発に手を出さない
- 10 Python言語学習後にWebフレームワーク
- 11 プログラミング言語Pythonの特徴
- 12 プログラミング言語Pythonの人気度
- 13 Python実行環境構築の種類
- 14 Pythonロードマップを元に本格的な学習を始めたい人へ
- 15 まとめ
Python初心者が作れるもの
Python初心者(プログラミング未経験)の場合、取り組めるプログラムは限られます。
なぜなら、プログラミング言語学習を始めたばかりだとアプリケーション開発まで学習が進んでいないからです。
そのため、Pythonの標準ライブラリや簡易的に組めるプログラムしか学習段階と並行して作成できないです。
Pythonの基礎知識を蓄えながら、Python初心者でも作れるものは以下になります。
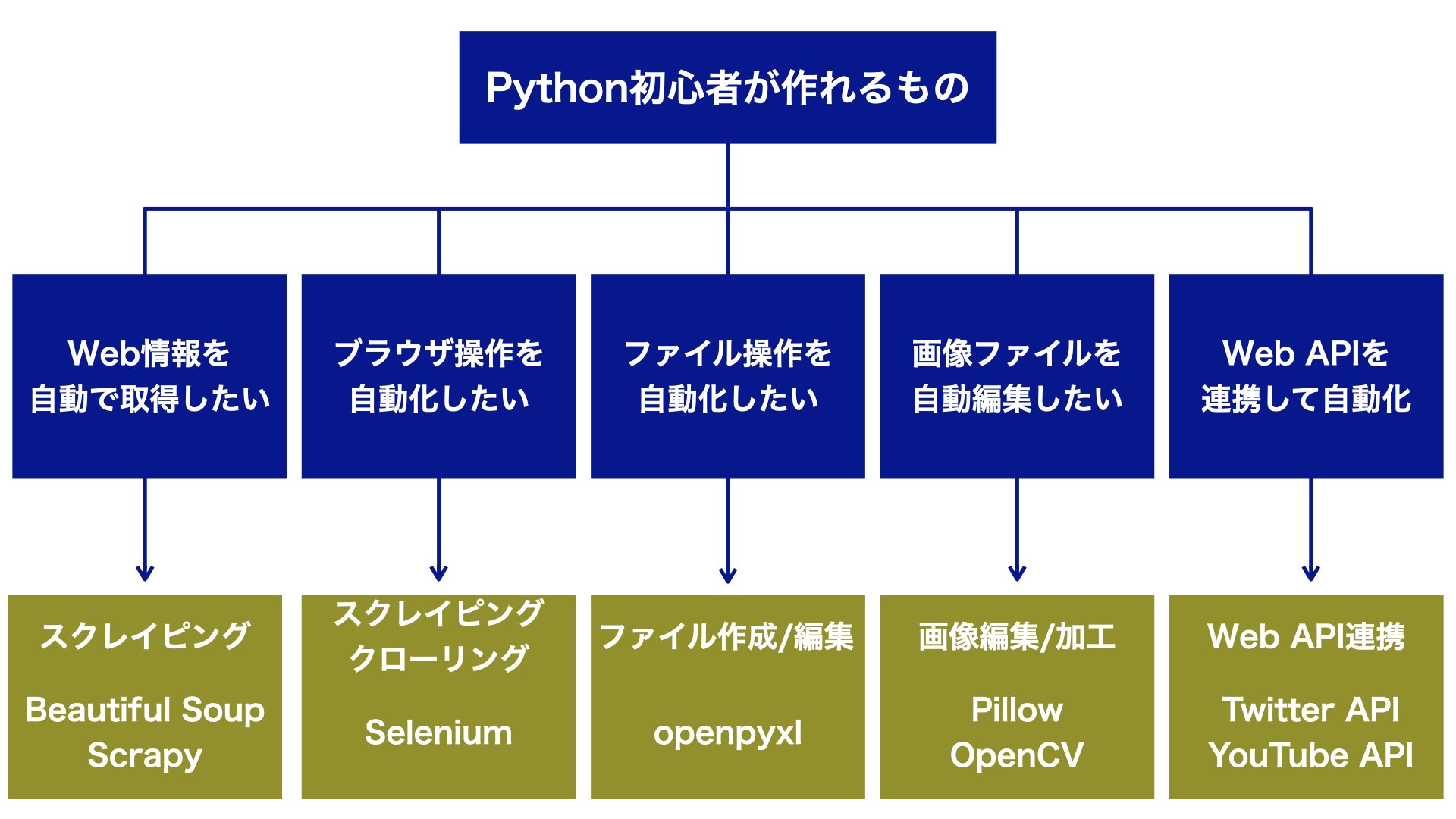
目的別に分類しましたが、Pythonにおける学習内容を解説します。
Pythonによるスクレイピング
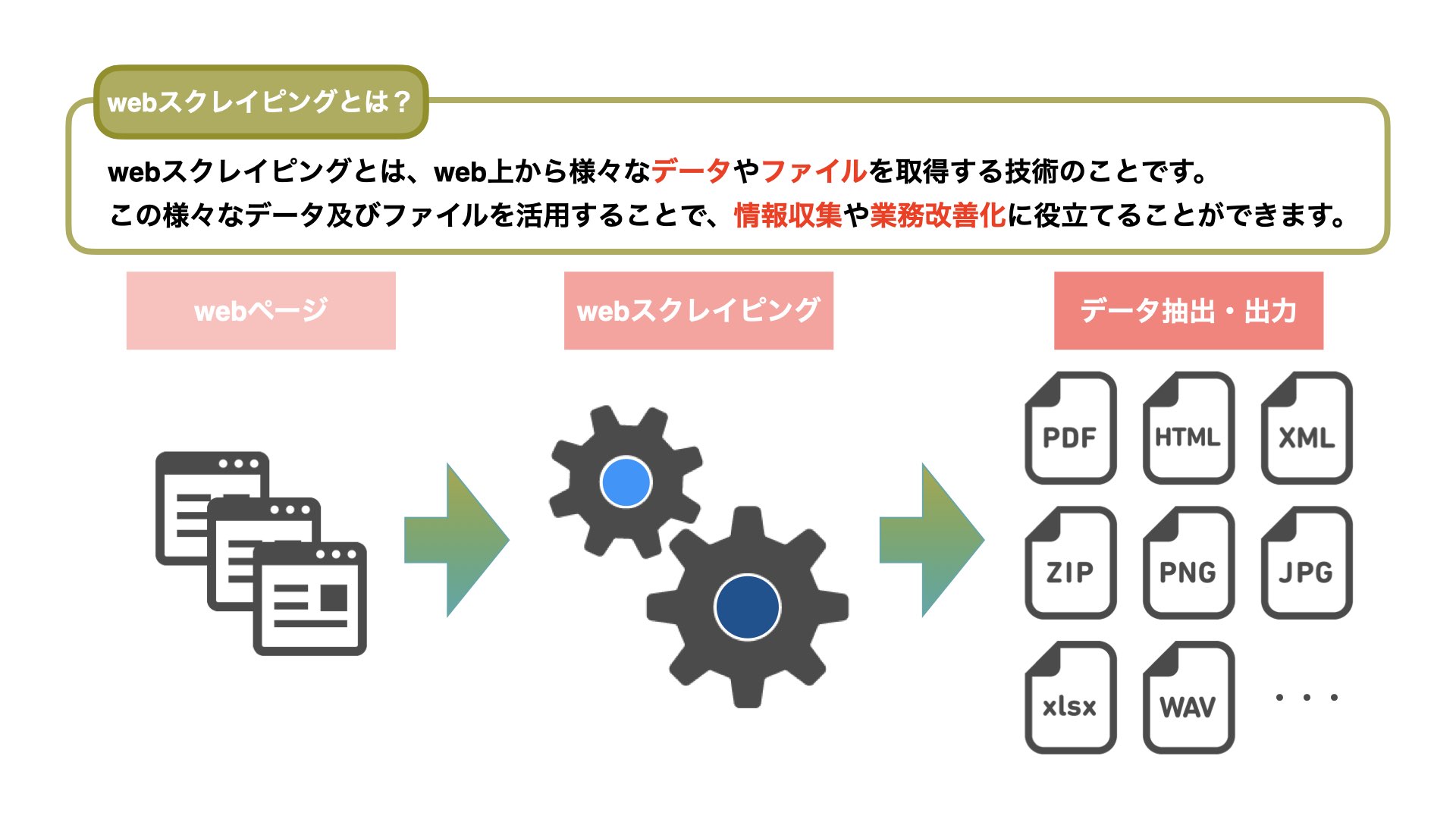
スクレイピングとは、Web情報を抽出する技術です。
必要に応じて抽出したデータを様々な整形ファイルに変化させ、出力します。
Pythonライブラリとして、Beautiful SoupやScrapyが利用されます。
筆者は、スクレイピング技術を利用して簡易的なWebサイト情報抽出ツールを数多く作成しています。
結果として、クラウドソーシングのランサーズにて上位20%である『認定ランサー』になれたので、非常に重宝しています。
Pythonによるスクレイピング技術の習得だけでも大きなメリットを獲得でき、Python言語学習から活用事例や副業まで取り組みたい人は合わせてこちらの記事も読んで頂けると幸いです。

すでにスクレイピング経験があって実践的なコードを理解したい人は、「【python】Selenium&BeautifulSoup&requestsによるスクレイピング:サンプルコードあり」で解説します。

【サンプルコード】Pythonによるスクレイピングで何ができる?
pythonによるスクレイピングで特に利用されるのが以下の3つです。
|
これら3つを利用できる環境を構築すれば、python初心者でも比較的簡単にプログラムを作れます。
例えば、以下のメルカリサイト内でキーワード検索した結果の各商品情報を全てスクレイピングすることができます。

以下のサンプルコードは、メルカリサイトの各商品ページに記載されている詳細情報を取得するプログラムです。
from selenium import webdriver
import time
import pandas
#キーワード入力
search_word = input("検索キーワード=")
# メルカリ
url = 'https://www.mercari.com/jp/search/?keyword=' + search_word
# chromedriverの設定とキーワード検索実行
driver = webdriver.Chrome(r"パス入力")
driver.get(url)
# ページカウントとアイテムカウント用変数
page = 1
item_num = 0
item_urls = []
while True:
print("Getting the page {} ...".format(page))
time.sleep(1)
items = driver.find_elements_by_class_name("items-box")
for item in items:
item_num += 1
item_url = item.find_element_by_css_selector("a").get_attribute("href")
print("item{0} url:{1}".format(item_num, item_url))
item_urls.append(item_url)
page += 1
try:
next_page = driver.find_element_by_css_selector("li.pager-next .pager-cell:nth-child(1) a").get_attribute("href")
driver.get(next_page)
print("next url:{}".format(next_page))
print("Moving to the next page...")
except:
print("Last page!")
break
# アイテムカウントリセットとデータフレームセット
item_num = 0
columns = ["item_name", "cat1", "cat2", "cat3", "brand_name", "product_state", "price", "url"]
df = pandas.DataFrame(columns=columns)
try: # エラーで途中終了時をtry~exceptで対応
# 取得した全URLを回す
for product_url in item_urls:
item_num += 1
print("Moving to the item {}...".format(item_num))
time.sleep(1)
driver.get(product_url)
item_name = driver.find_element_by_css_selector("h1.item-name").text
print("Getting the information of {}...".format(item_name))
cat1 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(1) div").text
cat2 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(2) div").text
cat3 = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(2) td a:nth-child(3) div").text
try: # 存在しない⇒a, divタグがない場合をtry~exceptで対応
brand_name = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(3) td a div").text
except:
brand_name = ""
product_state = driver.find_element_by_css_selector("table.item-detail-table tbody tr:nth-child(4) td").text
price = driver.find_element_by_xpath("//div[1]/section/div[2]/span[1]").text
price = price.replace("¥", "").replace(" ","").replace(",", "")
print(cat1)
print(cat2)
print(cat3)
print(brand_name)
print(product_state)
print(price)
print(product_url)
se = pandas.Series([item_name, cat1, cat2, cat3, brand_name, product_state, price, product_url], columns)
df = df.append(se, ignore_index=True)
print("Item {} added!".format(item_num))
except:
print("Error occurred! Process cancelled but the added items will be exported to .csv")
df.to_csv("{}.csv".format(search_word), index=False, encoding="utf_8")
driver.quit()
print("Scraping is complete!")ここでのコード解説は省略します。(別記事にて解説あり)
最終的に、CSVファイルとして出力した結果が以下の画像です。

取得したデータとして商品名・カテゴリー(3つ)・ブランド名・商品状態・金額・URLなど、様々な情報をスクレイピングすることができます。
pythonのSeleniumライブラリを利用したメルカリスクレイピングツールの作成に取り組んでみたい人は「【python】Seleniumによるメルカリのスクレイピングツール作成」で詳しく解説します。

Pythonによるクローリング
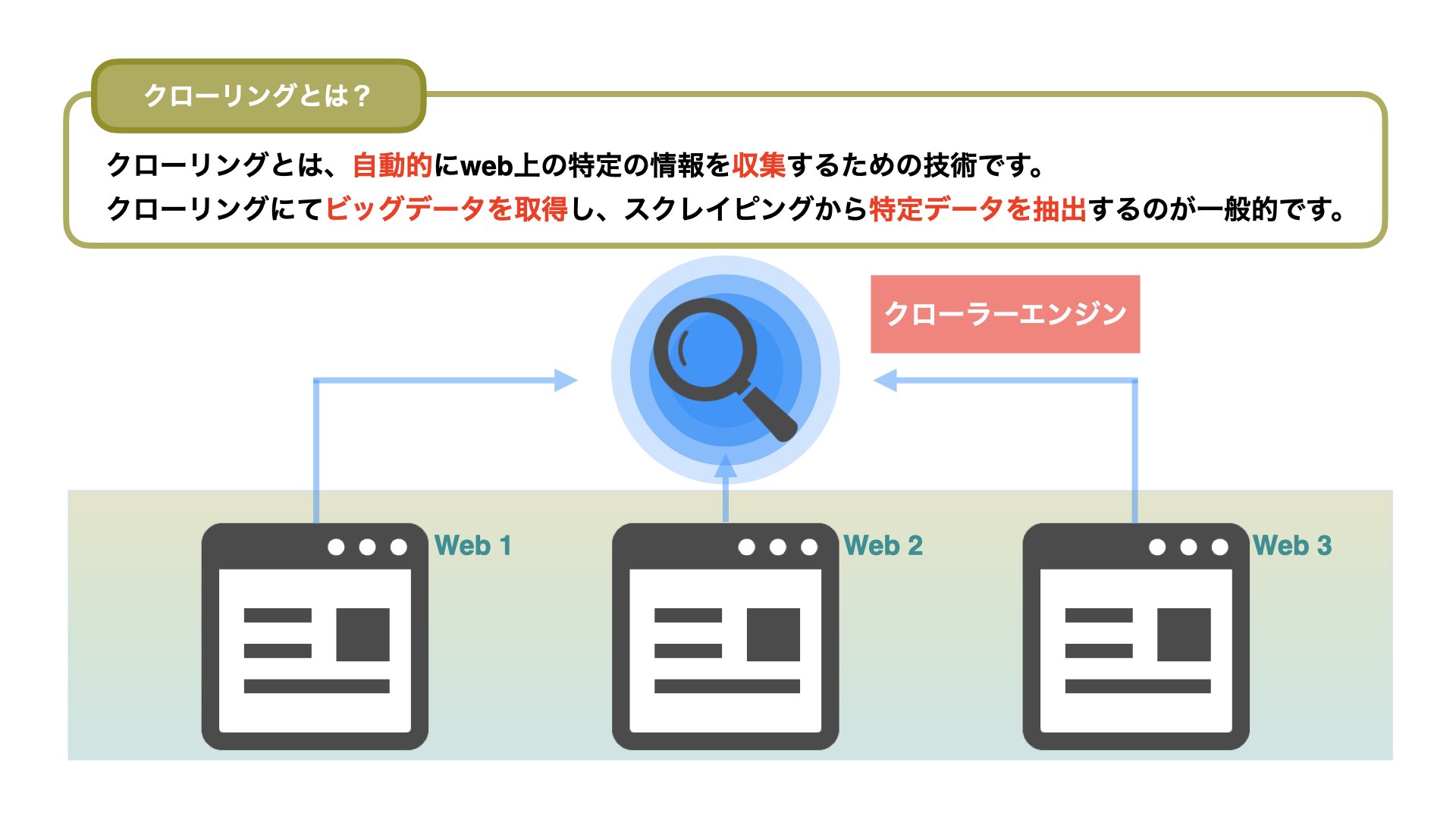
クローリングとは、特定のWebサイト情報を定期的に収集する技術です。
クローリングのメリットは、リアルタイム更新が頻繁なSNSや定期更新のあるWebサイトに有効です。
Pythonライブラリとして、Beautiful SoupやScrapy、Seleniumなども利用されます。
企業や個人事業主であっても、クラウドソーシングで依頼が頻繁に投稿されており、データ分析の一部として抽出データを利用されるようです。
比較的スクレイピングに類似した内容が多く、python初心者でも学習しやすいです。
特に、最近ではGoogle Colaboratoryと呼ばれるクラウド上の実行環境があるので、そちらと組み合わせるとローカル上PCに負担をかけず、定期実行されるプログラムを簡易的に作成できます。
Google Colaboratoryの環境構築から使い方まで解説した記事がありますので、合わせて読んで頂けると幸いです。

【サンプルコード】Pythonによるクローリングで何ができる?
pythonによるクローリングにおいても利用されるのが以下の3つです。
|
これら3つを利用できる環境を構築すれば、python初心者でもWebサイト内を巡回するプログラムが作れます。
例えば、以下のメルカリサイト内で検索した結果の商品一覧ページにて、売り切れ商品の商品名・金額・URLのみをページごとにクローリングしながら抽出します。

以下のサンプルコードは、メルカリサイトの商品一覧ページごとに商品名・金額・URLをクローリングにて抽出するプログラムです。
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import csv
import traceback
#キーワード入力
search_word = input("検索キーワード=")
# メルカリ
url = 'https://www.mercari.com/jp/search/?keyword=' + search_word + '&status_trading_sold_out=1'
# chromedriverの設定
driver = webdriver.Chrome(r"/Users/sugitanaoto/Desktop/chromedriver")
# 商品情報格納リスト
item_info = [['item_name', 'item_price', 'url']]
# ページカウント
page = 1
while True:
try:
print("Getting the page {} ...".format(page))
driver.get(url)
time.sleep(3)
# 文字コードUTF-8に変換後html取得
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
# tagとclassを指定して要素を取り出す
item_name = soup.find('div', class_='items-box-content clearfix').find_all('h3', class_='items-box-name font-2')
item_price = soup.find('div', class_='items-box-content clearfix').find_all('div', class_='items-box-price font-5')
item_url = soup.find('div', class_='items-box-content clearfix').find_all('a')
# アイテム数カウント
item_num = len(item_name)
print(item_num)
for i in range(0, item_num):
item_info.append([item_name[i].text, int(item_price[i].text.replace('¥','').replace(',','')), "https://www.mercari.com" + item_url[i].get('href')])
# next_page取得
try:
next_page = driver.find_element_by_css_selector("li.pager-next .pager-cell:nth-child(1) a").get_attribute("href")
url = next_page
print("next url:{}".format(next_page))
print("Moving to the next page...")
page += 1
except:
print("Last page!")
break
except:
message = traceback.print_exc()
print(message)
# 起動したChromeを閉じる
driver.close()
# csvファイルへ書き込み
with open('mercari-soldvalue.csv', 'w') as file:
writer = csv.writer(file, lineterminator='\n')
writer.writerows(item_info)ここでのコード解説は省略します。(別記事にて解説あり)
最終的に、CSVファイルとして出力した結果が以下の画像です。

特定の条件を付与しながらクローリング・スクレイピングを実行することができます。
pythonのSeleniumライブラリを利用したメルカリクローリングツールの作成に取り組んでみたい人は「【python】pandas&matplotlibを利用したメルカルスクレイピングデータ分析」で詳しく解説します。

PythonによるExcel(エクセル)自動化

おそらく、PC業務がメインとなる社会人であれば、一度はExcel(エクセル)の自動化を試みたいと考えたはずです。
それほどExcelの自動化は需要が高いです。
Pythonライブラリとして、openpyxlやpandasなどが利用されます。
Excelの自動化は、既存ファイルの整形に利用したり、webサイトにてスクレイピングして抽出したデータをExcel内で自動的に編集/出力するのが一般的です。
Python初心者であっても、Excelは馴染み深いソフトだと思いますので、自動化ツールを作成できれば、PC業務が効率化します。
Mac・Windowsともに利用できるようPythonを利用したExcel(エクセル)の読み書きを自動化する記事がありますので、興味があれば一読して頂けると幸いです。

【サンプルコード】Pythonによるファイル操作で何ができる?
pythonによるファイル操作において、利用されるのが以下の3つです。
|
これら3つを利用できる環境を構築すれば、python初心者でもファイル操作の自動化やデータ整形/分析、グラフ化/可視化に取り組めます。
例えば、クローリングにおけるサンプルコードにて取得したメルカリデータを整形し、売り切れ商品の価格相場をグラフ化/可視化できます。

クローリングにおけるサンプルコードで取得したデータにて、pandasを利用してキーワード「Python2年生」と文字列検索/一致させることで特定のデータに整形できます。
以下のサンプルコードは特定データへの整形とデータのグラフ化を実行するプログラムです。
import pandas as pd
import matplotlib.pyplot as plt
CSV_FILENAME = 'mercari-soldvalue.csv'
df = pd.read_csv(CSV_FILENAME, encoding="utf-8")
df_edit = df.query('item_name.str.contains("Python2年生", case=False)', engine='python')
print(df_edit)
df_edit.to_csv('edit_' + CSV_FILENAME)
# x軸、y軸の表示範囲
plt.xlim(0, 5000)
#plt.ylim(0, 300)
plt.grid(True)
plt.hist(df_edit['item_price'], alpha=1.0, bins=500)
plt.show()ここでのコード解説は省略します。(別記事にて解説あり)
最終的に、特定データに整形したCSVファイルを読み込み、matplotlibを利用してデータをグラフ化した結果が以下の画像です。

pandasによるデータ整形やmatplotlibによるデータのグラフ化など、ファイル操作ができるとpythonの活用方法が広がります。
pandas&matplotlibを利用したデータ整形/グラフ化の作成に取り組んでみたい人は「【python】pandas&matplotlibを利用したメルカルスクレイピングデータ分析」で詳しく解説します。
Pythonによる顔認識や物体検知
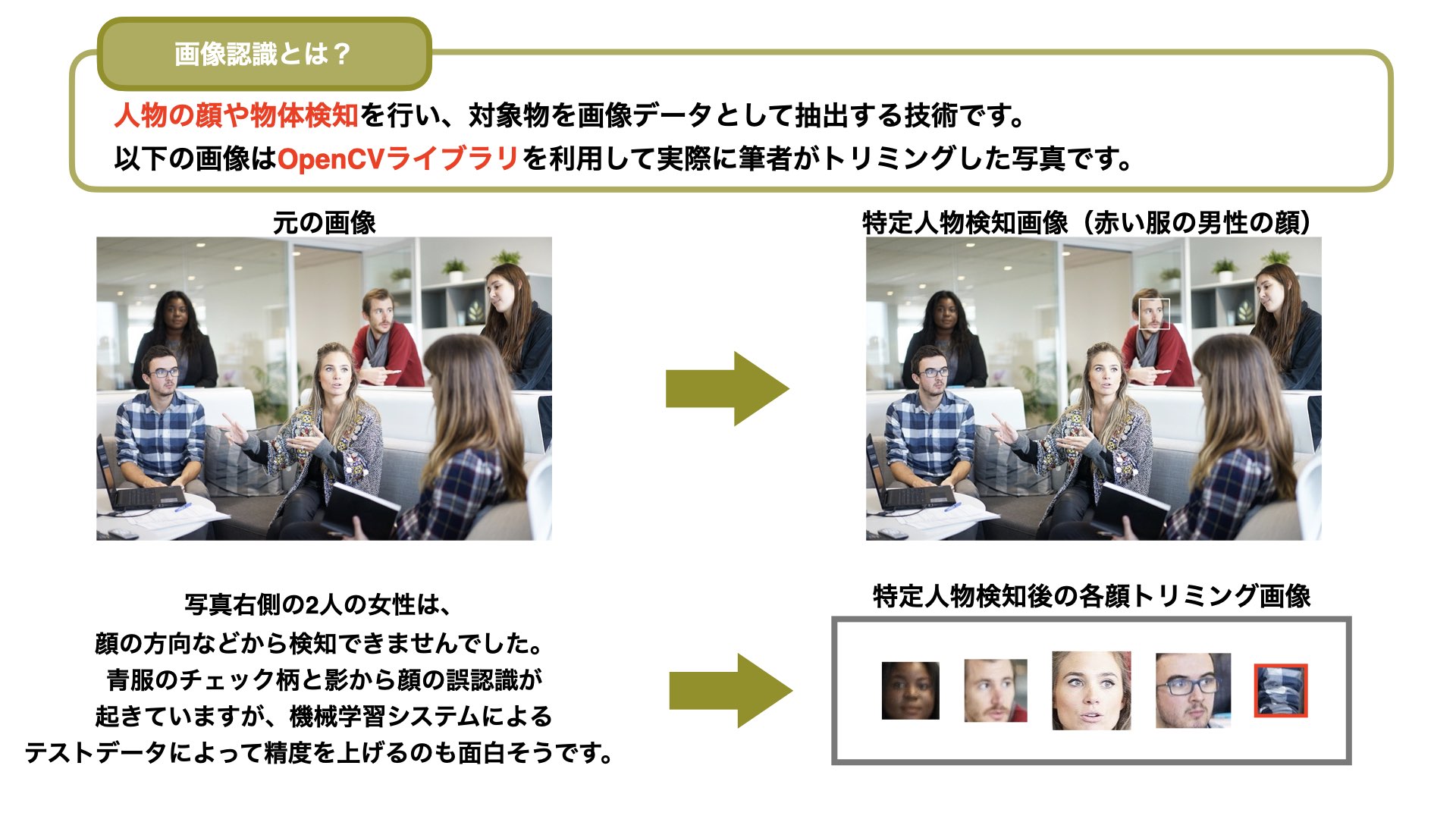
Pythonでは、顔認識や物体検知などのプログラムも作成できます。
SNOW(スノー)などでも利用される技術で、コロナウィルスの影響もあり大型スーパーやショッピングモールで、特定人物の顔認識から体温検知するために利用されるなど、画像・動画データからの物体検知が注目されています。
AR技術にも利用されるケースもあります。
上記の画像をトリミング画像(画像検出)したサンプルコードを記載しておきます。
import cv2
image = cv2.imread('指定するファイル名.jpg')
cascade_file = 'haarcascade_frontalface_alt2.xml'
cascade_face = cv2.CascadeClassifier(cascade_file)
# 顔を探して配列で返す
face_list = cascade_face.detectMultiScale(image, minSize=(20, 20))
for i, (x, y, w, h) in enumerate(face_list):
trim = image[y: y+h, x:x+w]
cv2.imwrite('cut' + str(i+1) + '.jpg', trim)
#HAAR分類器の顔検出用の特徴量
cascade_path = r'haarcascade_frontalface_alt2.xml'
image_path = "指定するファイル名.jpg"
color = (255, 255, 255) #白
#ファイル読み込み
image = cv2.imread(image_path)
#グレースケール変換
image_gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
#カスケード分類器の特徴量を取得する
cascade = cv2.CascadeClassifier(cascade_path)
facerect = cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=1, minSize=(1, 1))
print("face rectangle")
print(facerect)
if len(facerect) > 0:
#検出した顔を囲む矩形の作成
rect = facerect[1]
cv2.rectangle(image, tuple(rect[0:2]),tuple(rect[0:2]+rect[2:4]), color, thickness=2)
#認識結果の保存
cv2.imwrite("../desktop/detected.jpg", image)
PythonによるWeb API連携
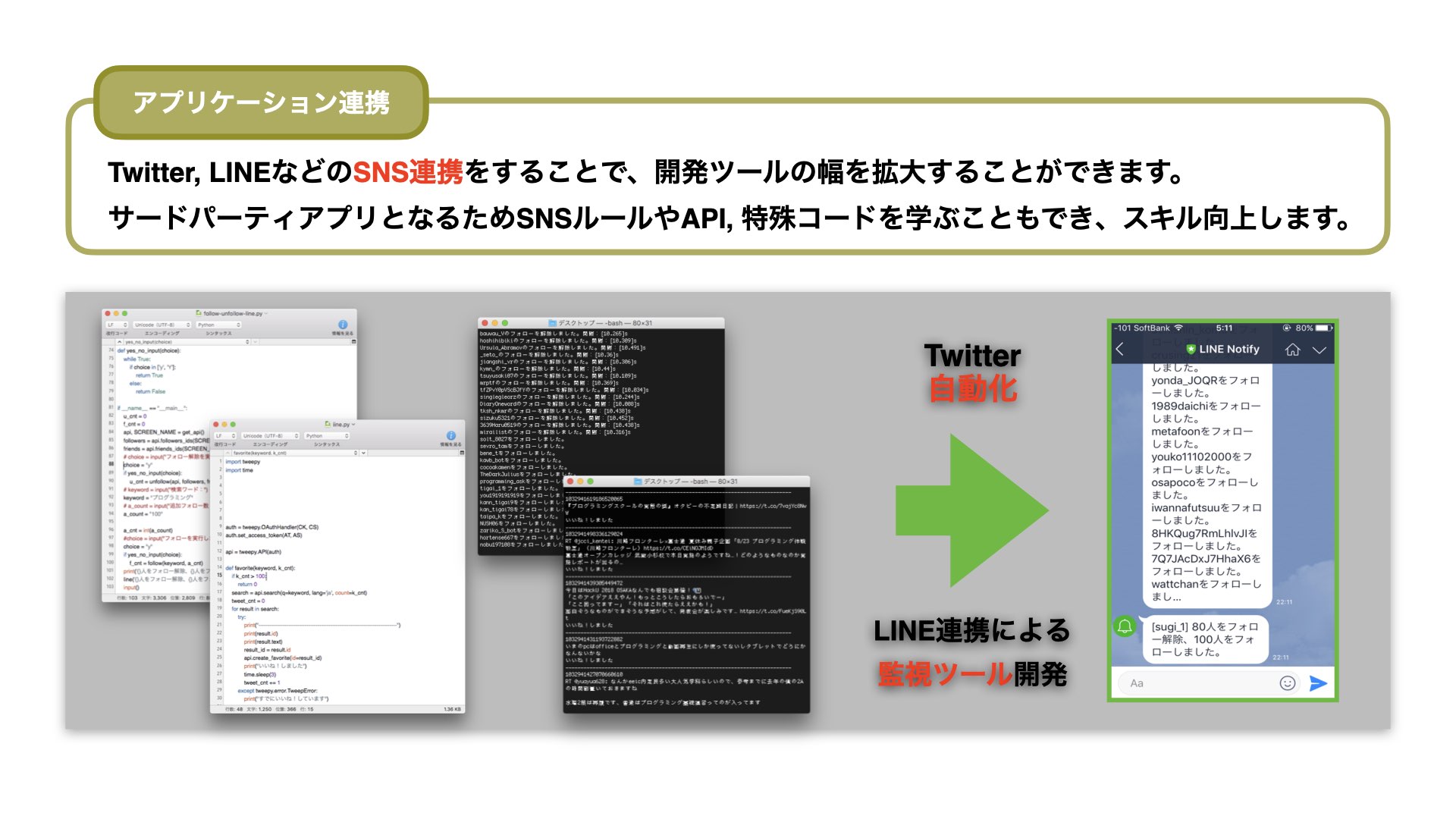
TwitterやInstagram、LINEなど様々なSNSによってWeb APIを利用できます。
ライブラリやAPI申請など環境を整えれば、今すぐにでも利用できる有効的なプログラムです。
簡易的なプログラムで、Twitterの自動ツイート(botと呼べれるもの)やフォロー・アンフォロー・いいね・リツイートも自動化できます。
Web APIを連携させることで、Twitter自動化の監視結果をLINE上で確認したり、多くのメリットが享受できます。
詳しいPython活用事例と詳細なPythonエンジニアスキルを知りたい人は、「Python活用事例から導くPythonにできること・スキル・学習方法を解説!」で解説します。

YouTube Data API連携したFlaskによる動画データ分析アプリ開発
筆者が個人的にYouTube Data APIを連携させたFlaskによる簡易的な動画データ分析アプリを開発しました。

動画データ分析アプリでは、以下の開発工程を組んでいます。
|
全て工程ごとの作業とファイル構成/実装コードなど、画像とサンプルコードで解説しています。
Pythonを利用してFlask(フレームワーク)でアプリ開発してみたい人は「【Python】Flask+YouTube Data APIによる動画データ分析アプリ開発」を一読ください。

Python初心者が最初に作る簡単なプログラム【Webアプリ編】
おそらく現役エンジニアのほとんどが最初に作る簡単なプログラムは、WebアプリケーションであればToDoアプリです。

ToDoアプリを最初に取り組むべき理由は、以下の内容です。
|
VS Code等のテキストエディタやローカル環境によるアプリケーションサーバーの構築などを実践的に学べます。
フロントエンド/バックエンドといったHTML/CSS/Pythonなどを利用して、Webアプリケーションを構成しているフォルダやファイルを作成しながらコード実装まで習得できます。
CRUD機能(Create:作成, Read:読み込み, Update:更新, Delete:削除)といったアプリの根幹となる最も重要な機能を理解できます。
DB(データベース)連携を知ることで、どのようにアプリケーション内でデータを保持しているか学べます。
そして、ネット環境でアプリがどのように世の中へ公開されるか学ぶことができます。
PythonのWebフレームワークであるFlaskでToDoアプリ開発をしてみたい人は「【Python】FlaskによるToDoアプリケーション作成/開発」を一読ください。
全て工程ごとの作業とファイル構成/実装コード/アプリ公開など、画像とサンプルコードで解説しています。

就職支援実績あり!おすすめオンラインプログラミングスクール
独学でプログラミング学習の限界を感じている人におすすめのオンラインプログラミングスクールをご紹介します。
ただし、注意する点として『スクールの質が高い=あなたに最適なスクール』には必ずしもならないため、必ずカウンセリングを受けてください。
カウンセリングを受けないで決めてしまうとお金を無駄にする可能性があります。
| スクール名 | 最短受講期間 | 料金(税込) | スクールの概要 |
|---|---|---|---|
| TechAcademy | 4週間プラン(1ヶ月/コース) | 174,900円/コース | オンライン学習サービス1週間の無料体験可能/Python・AI・データサイエンスコースなど複数コース受講のセット割引プランあり |
| CodeCamp | 2ヶ月 | 198,000円 | マンツーマンでPythonを学べ、レッスン対応時間が長く、早朝・深夜の時間帯もオンラインで受講可能/無料カウンセリングあり |
TechAcademy(テックアカデミー)

TechAcademy(テックアカデミー)は、累計3万人以上の受講実績のある人気プログラミングスクールです。
現役ITエンジニアのパーソナルメンター(講師)による学習サポートやチャットでの質問対応ができ、プログラミング未経験/初心者でも学びやすいと評判のオンラインスクールです。
|
学べるコースはPython/はじめてのプログラミング/Web制作・システム開発系など多数のコースがあり、セット割引を利用して複数のセット受講も可能です。
現役エンジニアのメンターと週2回のメンタリング、直接プロからプログラミングやキャリアについて学べる学習環境があります。
また、毎日15時~23時の8時間はオンラインの質問対応、提出課題には丁寧なレビューがもらえるなど受講者の評判が良いオンラインプログラミングスクールです。
さらにメンタリング/チャットでの質問対応状況など、オンライン学習サービスを確認できる1週間の無料体験がおすすめです。
CodeCamp(コードキャンプ)

CodeCamp(コードキャンプ)は、現役エンジニア講師のマンツーマンレッスンによる丁寧な指導が人気/評判のオンラインプログラミングスクールです。
累計受講者数3万人以上、研修導入企業300社以上など実績も豊富なスクールになります。
|
これらを含め、Python/Webデザイン/アプリ開発/オーダーメイドなど、豊富なカリキュラム内容です。
マンツーマンレッスンの対応可能な時間帯は、毎日7時~23時40分と他のプログラミングスクールより長く、CodeCampは早朝や深夜でも受講できます。
そのため、仕事・学業をしながら受講しやすい点がおすすめと口コミで評価されています。
また、自分で講師を指名できる点、Pythonについての質問や講師にエンジニアとしてのキャリアや就職/転職の相談も可能です。
CodeCampに興味ある人は、詳しいレッスン内容や学習サービスについて確認でき、受講料金の1万円割引クーポンももらえる無料カウンセリングの利用がおすすめです。
Python初心者はアプリケーション開発に手を出さない
Pythonの言語学習から始めている人であれば、いきなりアプリケーション開発から手を出してはいけません。
なぜなら、プログラミング言語Pythonの学習途中であれば、プログラミングの概念やコード記述を理解している段階で、アプリケーションの動作原理などは理解できていないからです。
要するに、アプリ開発における知識の点が線として結びついていないため、理解する前に膨大な学習内容で挫折しやすいです。
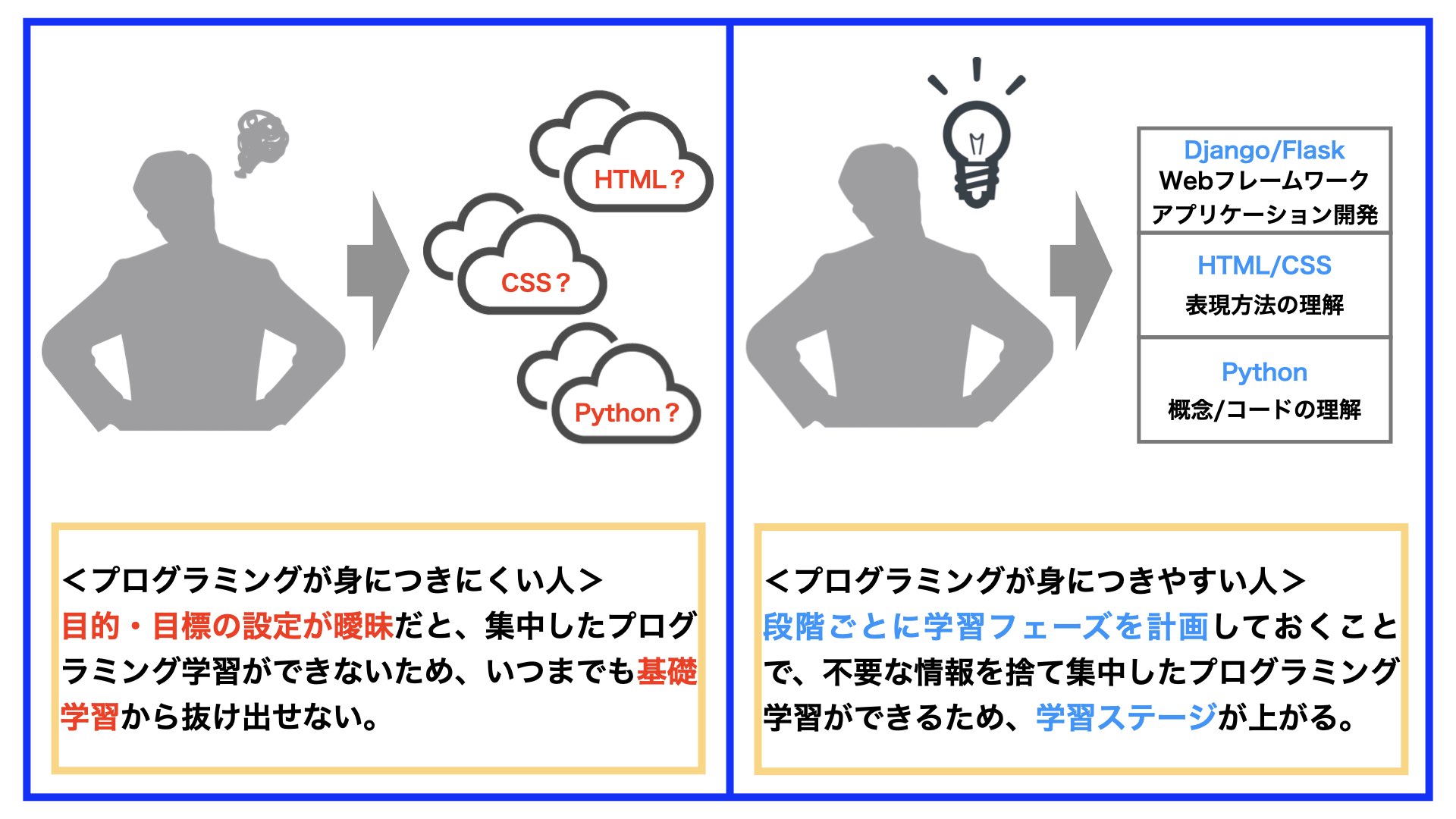
曖昧な言語学習のまま多くの情報に手を出してしまうと、かえって学習の妨げになります。
自身で目標を立てながら、一つずつスキルを身につけていきましょう。
Python言語学習後にWebフレームワーク
Pythonの言語学習後に、Webフレームワークと呼ばれる概念を理解しましょう。
Pythonであれば、DjangoやFlaskといったWebフレームワークです。
これらWebフレームワークも特徴が存在するので、把握しておきましょう。
Pythonは多くのフレームワークが存在するので、選択に迷わないために詳しい内容が知りたい人は合わせてこちらの記事も読んで頂けると幸いです。

プログラミング言語Pythonの特徴
プログラミング未経験あるいは初心者には、Pythonを強くおすすめしたいです。
主に以下の理由が挙げられます。
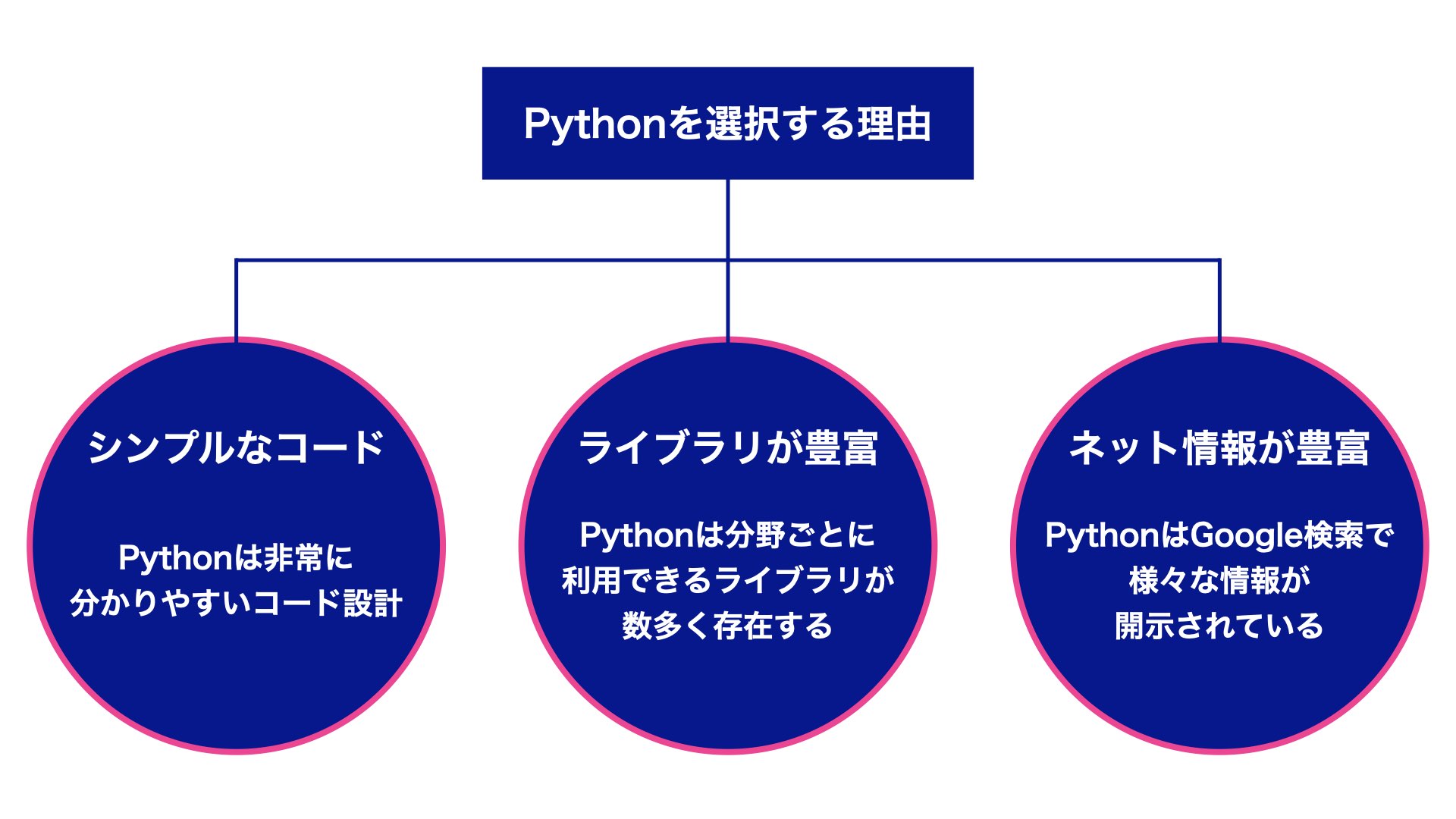
Pythonはシンプルなコード設計
基本的に誰が見ても理解しやすいデザインコードを”可読性が高い”と言います。
Pythonは他言語に比べて記述量が少ないです。
文法・構文などのシンプルな構成が特徴であり、誰が読み書きしても理解しやすいコード設計になっています。
Pythonはライブラリが豊富
先ほども上述した内容通り、様々な利用価値のあるライブラリが存在します。
特に、機械学習やAIの注目が高まったため、数学的ライブラリの豊富さが特徴です。
Pythonはネット情報が豊富
本記事も一つのネット情報となりますが、検索結果から得られる情報が豊富に存在します。
これはPython利用者が多いことも起因します。
また、言語ランキングや検索回数も要因だと思いますが、後述します。
プログラミング言語Pythonの人気度
PYPL(PopularitY of Programming Language)と呼ばれる指標があります。
PYPLは、Google検索エンジンを利用しプログラミング言語チュートリアルが検索された回数を集計、対象のプログラミング言語がどれほど話題となっているかを表したものになります。
下の画像は、執筆時点での2021年2月までの集計結果になります。
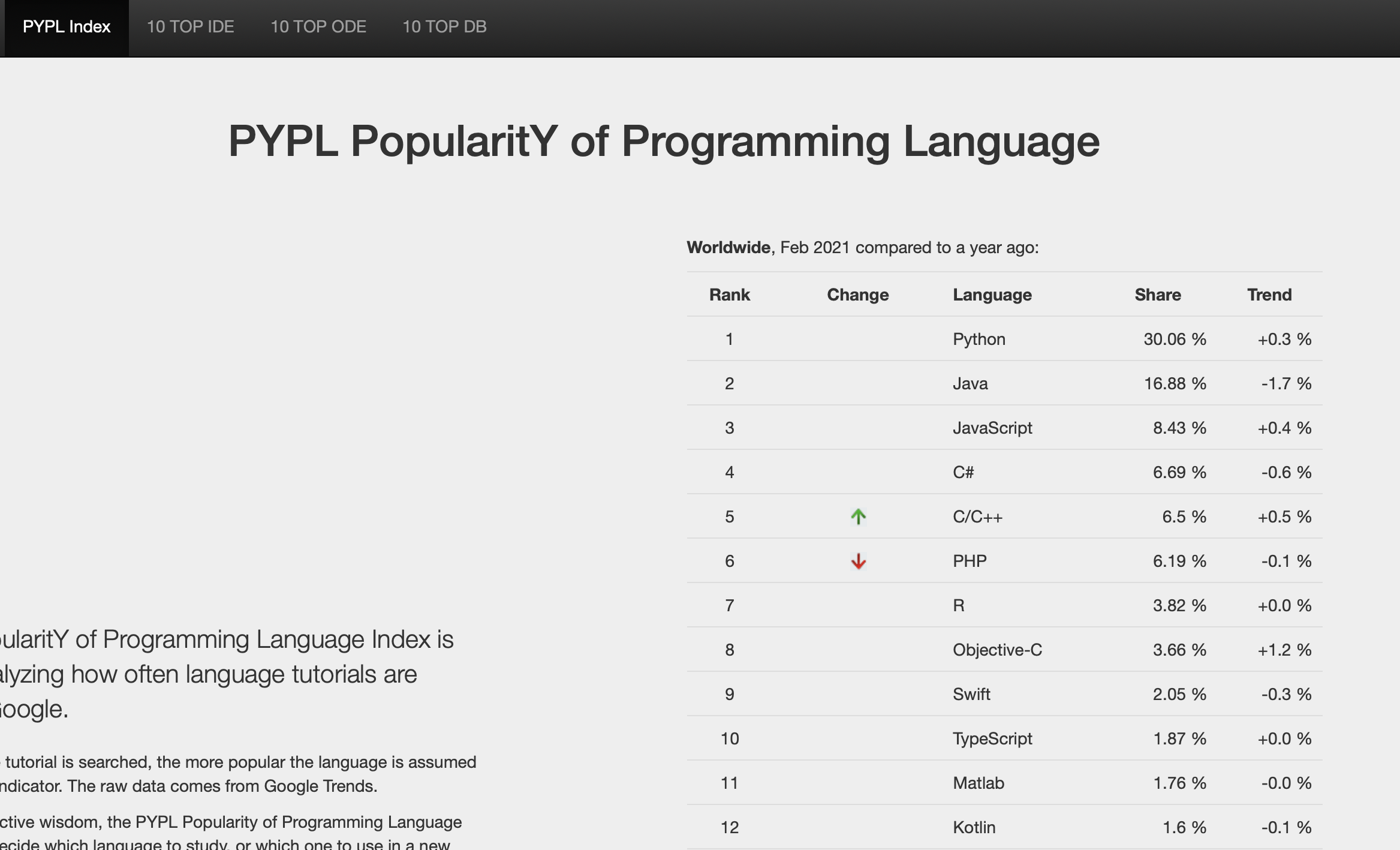
海外の企業(Googleと始めとするテクノロジー企業)がPythonを採用したことから、日本でもビジネス利用として普及し、今ではプログラミング学習に最適な言語の一つとして認知されるようになりました。
また、Googleトレンドなどの検索回数なども、頻繁に情報が求められているプログラミング言語だと判断できます。
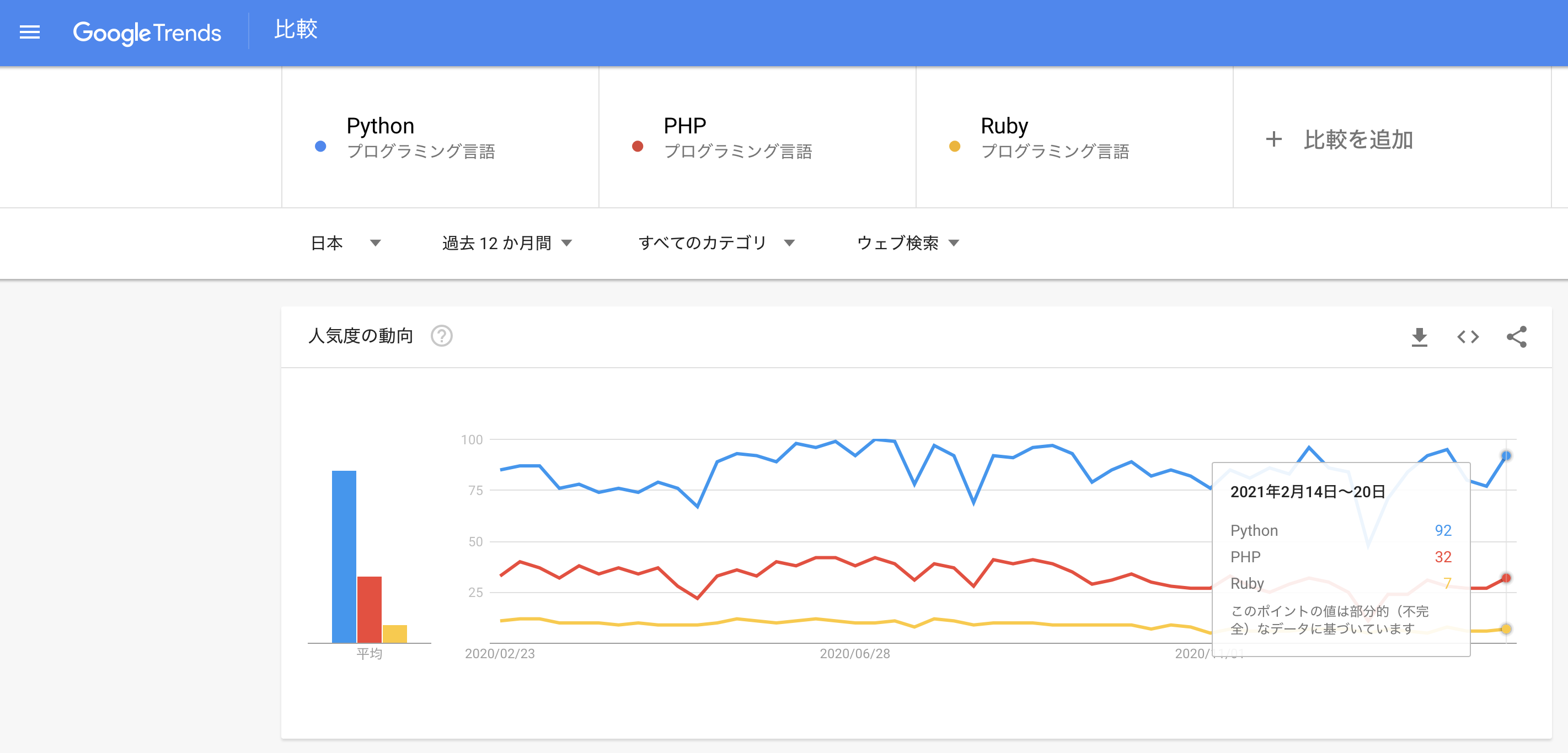
様々な観点から、今後も需要が高まっていく言語だと予想されます。
Python実行環境構築の種類
そもそも、Python実行環境を用意する上で様々な構築方法があります。
|
多くのPython実行環境構築の方法が存在します。
ただし、複数のPython実行環境の構築方法を知ってもどれから手をつければよいか、これからプログラミングを始めるPython初心者は迷ってしまいます。
おすすめはGoogle ColaboratoryによるPython実行環境構築です。
Googleアカウントさえ持っていれば、ブラウザとインターネットを利用してすぐにでもPython環境を実現できるサービスです。
Google ColaboratoryにてPythonが利用できるまでのインストール手順は、以下の流れです。
|
特に、環境構築といった学習コストがかからない点は初心者にとっても魅力的です。
ローカルPCでPython環境構築に困っている人は「【Python】Google Colaboratoryの使い方とメリットを徹底解説!」で解説します。
全て画像付きで解説しており、直感的操作で環境構築できます。(3分もかからないはずです。)
開発環境の状況に応じて、使い分けられると便利なのでお手隙のタイミングで環境構築しておきましょう。
Pythonロードマップを元に本格的な学習を始めたい人へ
おそらくプログラミング未経験からPythonあるいはプログラミング活用を図りたい人は、以下の考えが存在すると思います。
|
上記の悩みや課題をPythonロードマップとして言語学習から転職までを目標プロセスに落とし込んで作成しました。

あなたの考えるエンジニア像のゴールに合わせたオンラインプログラミングスクールが選べる情報も公開しているので、一度読んでみてください。

まとめ

|
これらの技術をPythonの言語学習と並行して作るのがおすすめです。
必ず言語学習を終えたタイミングで、HTML/CSSやWebフレームワークを理解し、アプリケーション開発に取り組んでいきましょう。
Python学習を効率的に取り組みたい人は、こちらの記事も合わせて一読ください。


























