
python初心者にとってスクレイピング技術は取り組みやすいですが、取得データの活用に悩む人がいます。
pythonでは、pandasといったデータ整形のライブラリやmatplotlibといったデータのグラフ化に役立つライブラリが存在します。
|
これらの悩みを解決しながら、本記事ではメルカリサイトの特定商品価格の相場をデータ分析します。
最終的には、商品価格の相場をデータ分析する中でseleniumによるスクレイピングとpandas&matplotlibの活用方法が理解できます。
また、筆者自身クラウドソーシングサイトであるランサーズにてコンスタントに毎月10万円を稼ぎ、スクレイピング業務にて2021年6月に最高報酬額である30万円を突破しました。
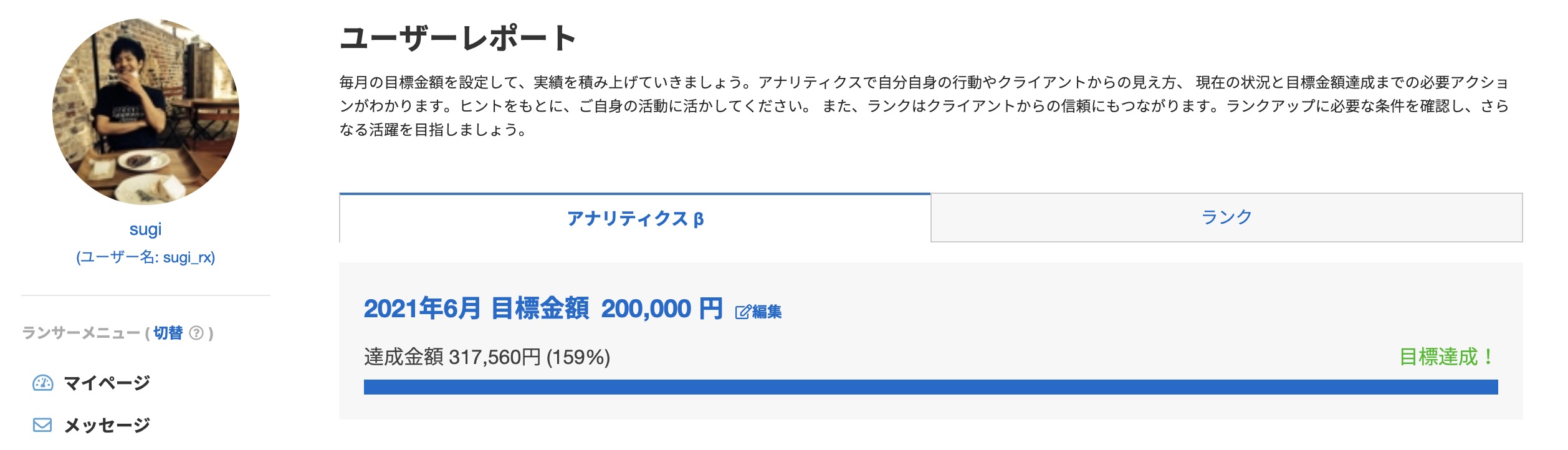
年間報酬額も100万円突破するなど、実務的なスクレイピング技術の活用方法や具体的な稼ぎ方について、一定の記事信頼を担保できると思います。
プログラミングの中でもスクレイピング技術は習得することで、副業に十分活かせる武器になると先にお伝えしておきます。
ぜひ、本記事のサンプルコードなどを利用して様々な場面で活用してみてください。
目次
pythonによるメルカリサイトスクレイピングの流れ
はじめに、メルカリサイトのスクレイピング処理を確認します。
自身でも確認したい人は、メルカリのURLにアクセスして表示形式を確認してみてください。
|
最終的に、出力したCSVファイルを元にデータ分析していきます。
スクレイピングの流れをサイト画像で確認します。
メルカリのサイトへアクセス後、キーワード「python 本 スクレイピング」で検索します。

キーワード「python 本_スクレイピング」で検索後、以下の商品一覧ページが表示されます。

商品一覧ページは、商品画像と値段が表示されて左側に詳細検索も選択できる画面になります。
また、今回は詳細検索を利用して売り切れている商品の価格帯を調べます。

実際にメルカリを利用して商品を出品する人は、出品物の金額設定として参考に出品価格を確認することがあると思います。
手作業による全ての商品価格の確認は限界があります。
そのため、本記事ではpythonを利用して特定キーワードによる検索にて相場を調べていきます。
メルカリにおける価格データのスクレイピング
ここから任意の.pyファイルを作成してコードを実装します。
from bs4 import BeautifulSoup from selenium import webdriver import time import csv import traceback
メルカリサイトをクローリングするためにseleniumを利用します。
BeautifulSoupは、クローリングしているページから商品情報を取得するために利用します。
time, csv, tracebackなどは適宜スクレイピングの時間調整、CSVファイルエクスポート、エラー時の対応等で利用します。
SeleniumはWebドライバーも必要になるため、適宜環境構築します。
pip install BeautifulSoup pip install selenium
pipを利用することでライブラリをインストールすることができます。
#キーワード入力
search_word = input("検索キーワード=")
# メルカリ
url = 'https://www.mercari.com/jp/search/?keyword=' + search_word + '&status_trading_sold_out=1'
# chromedriverの設定
driver = webdriver.Chrome(r"パス入力")
# 商品情報格納リスト
item_info = [['item_name', 'item_price', 'url']]
# ページカウント
page = 1キーワード入力用の変数は、プログラム実行後にキーワード入力できるよう記述しています。
url変数では、メルカリのURLとsearch_word変数を組み合わせています。
Webdriverを利用してchromeへアクセスする準備を行います。
商品情報を格納するリストおよび商品一覧のページカウント変数を用意しておきます。
while True:
try:
print("Getting the page {} ...".format(page))
driver.get(url)
time.sleep(3)
# 文字コードUTF-8に変換後html取得
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
# tagとclassを指定して要素を取り出す
item_name = soup.find('div', class_='items-box-content clearfix').find_all('h3', class_='items-box-name font-2')
item_price = soup.find('div', class_='items-box-content clearfix').find_all('div', class_='items-box-price font-5')
item_url = soup.find('div', class_='items-box-content clearfix').find_all('a')
# アイテム数カウント
item_num = len(item_name)
print(item_num)
for i in range(0, item_num):
item_info.append([item_name[i].text, int(item_price[i].text.replace('¥','').replace(',','')), "https://www.mercari.com" + item_url[i].get('href')])
# next_page取得
try:
next_page = driver.find_element_by_css_selector("li.pager-next .pager-cell:nth-child(1) a").get_attribute("href")
url = next_page
print("next url:{}".format(next_page))
print("Moving to the next page...")
page += 1
except:
print("Last page!")
break
except:
message = traceback.print_exc()
print(message)
# 起動したChromeを閉じる
driver.close()
# csvファイルへ書き込み
with open('mercari-soldvalue.csv', 'w') as file:
writer = csv.writer(file, lineterminator='\n')
writer.writerows(item_info)while文を利用して検索結果の商品一覧ページ全てを取得するまでループさせます。
try文では、商品一覧ページごとに商品名・商品価格・商品ページURLを取得していきます。
取得したデータは、商品情報を格納するリストに追加(append)していきます。
BeautifulSoupでパース(HTML解析)やfindメソッドによるデータ取得後に、アイテムカウントを行い、カウント数に応じてリストに格納していることがわかると思います。
別ページへ遷移する場合もtry-except文を利用して次ページURLを取得できた場合をループ処理、できなかった場合をbreakとし、ループ処理を終えられるよう記述しています。
最後に、起動していたブラウザを閉じて商品情報を格納していたリストをCSVファイルに書き込みエクスポートします。
なお、メルカリサイトの商品一覧ページから各商品ページに遷移し、各商品の詳細情報を取得してみたい人は「【python】Seleniumによるメルカリのスクレイピングツール作成」で解説します。

メルカリスクレイピングによるCSVファイルデータ
メルカリにおける全体のサンプルスクレイピングコードは以下です。
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import csv
import traceback
#キーワード入力
search_word = input("検索キーワード=")
# メルカリ
url = 'https://www.mercari.com/jp/search/?keyword=' + search_word + '&status_trading_sold_out=1'
# chromedriverの設定
driver = webdriver.Chrome(r"/Users/sugitanaoto/Desktop/chromedriver")
# 商品情報格納リスト
item_info = [['item_name', 'item_price', 'url']]
# ページカウント
page = 1
while True:
try:
print("Getting the page {} ...".format(page))
driver.get(url)
time.sleep(3)
# 文字コードUTF-8に変換後html取得
html = driver.page_source.encode('utf-8')
soup = BeautifulSoup(html, "html.parser")
# tagとclassを指定して要素を取り出す
item_name = soup.find('div', class_='items-box-content clearfix').find_all('h3', class_='items-box-name font-2')
item_price = soup.find('div', class_='items-box-content clearfix').find_all('div', class_='items-box-price font-5')
item_url = soup.find('div', class_='items-box-content clearfix').find_all('a')
# アイテム数カウント
item_num = len(item_name)
print(item_num)
for i in range(0, item_num):
item_info.append([item_name[i].text, int(item_price[i].text.replace('¥','').replace(',','')), "https://www.mercari.com" + item_url[i].get('href')])
# next_page取得
try:
next_page = driver.find_element_by_css_selector("li.pager-next .pager-cell:nth-child(1) a").get_attribute("href")
url = next_page
print("next url:{}".format(next_page))
print("Moving to the next page...")
page += 1
except:
print("Last page!")
break
except:
message = traceback.print_exc()
print(message)
# 起動したChromeを閉じる
driver.close()
# csvファイルへ書き込み
with open('mercari-soldvalue.csv', 'w') as file:
writer = csv.writer(file, lineterminator='\n')
writer.writerows(item_info)サンプルのスクレイピングコードを実行した結果が以下の画像です。

キーワード「python 本 スクレイピング」と売り切れによる詳細検索後、取得データ件数は792件になりました。
ひとまずメルカリの商品価格を取得できたため、データ分析のテストデータを準備することができました。
Selenium、BeautifulSoup、requestsといったライブラリを実践的に活用したい人は「【python】Selenium&BeautifulSoup&requestsによるスクレイピング:サンプルコードあり」で解説します。

メルカリのスクレイピングデータのグラフ化/可視化
ここからメルカリのスクレイピングデータをグラフ化/可視化していきます。
CSVファイルの商品データを確認して、商品名をさらに特定した状態で価格の相場をグラフ化していきます。
CSVファイルの商品名を確認してみると、「Python2年生」というワードが多く存在していることが分かりました。
そこで、「Python2年生」に文字列を絞って特定商品の価格帯を可視化します。
改めて、別の任意.pyファイルを作成してコードを実装します。
import pandas as pd
import matplotlib.pyplot as plt
CSV_FILENAME = 'mercari-soldvalue.csv'
df = pd.read_csv(CSV_FILENAME, encoding="utf-8")
df_edit = df.query('item_name.str.contains("Python2年生", case=False)', engine='python')
print(df_edit)
df_edit.to_csv('edit_' + CSV_FILENAME)
# x軸、y軸の表示範囲
plt.xlim(0, 5000)
#plt.ylim(0, 300)
plt.grid(True)
plt.hist(df_edit['item_price'], alpha=1.0, bins=500)
plt.show()データ整形/抽出に利用するpandasとグラフ化に利用するmatplotlibをインポートします。
pip install pandas pip install matplotlib
pipを利用して適宜インストールすれば利用できます。
df(DataFrame)の変数を用意して、pandas(pd)にてメルカリのスクレイピングデータを持つCSVファイルを読み込みます。
df_edit変数で「Python2年生」を文字列検索して、ヒットした行(rows)を格納します。
文字列検索でヒットした行のみを格納したデータで改めてCSVファイルに出力します。
以下の画像が文字列検索で抽出したデータのみのCSVファイルです。

きれいにまとめることができました。
この際、ヒットした件数は212件になりました。
matplotlibを利用してグラフのx軸とy軸の範囲を定めています。
最終的に、item_priceを用いてヒストグラフにて表示させています。
以下の画像が文字列検索にて絞った特定商品の価格におけるヒストグラフです。

相場価格として、1500円から2000円までの金額が多いことが分かります。
このように、特定商品の価格相場を割り出し、データ分析として利用できるのがPythonです。
ぜひ、データ分析やデータのグラフ化/可視化に利用してみてください。
スクレイピング技術で用いる各種ライブラリを詳しく理解したい人は「【python】スクレイピングで利用する各種ライブラリと稼ぐための活用方法」で解説します。
まとめ
pythonでスクレイピング処理を考えることが重要です。
|
スクレイピング技術を身につけることでデータ活用に転用できます。
スクレイピング技術で利用される主なライブラリは以下です。
|
本記事では、BeautifulSoupとSeleniumの利用方法を解説しました。
また、スクレイピングデータを利用してデータ整形やグラフ化/可視化する際に活用できるライブラリは以下です。
|
本記事では、メルカリサイトをサンプルとして活用しました。
スクレイピングの対象サイトによって活用方法は様々なため、利用シーンに合わせて活用してみてください。
python初心者でも作りやすいものを詳しく知りたい人は「【認定ランサー】Python初心者が作れるものを目的別に学習方法解説!」で解説します。
























