
pythonのライブラリであるBeautifulSoupやSeleniumを活用することで、簡単にWebスクレイピングを実現できます。
様々な会社でDX化(Digital Transformation)が囁かれる今、業務効率化に利用できる技術は効果的です。
|
これらの悩みを解決しながら、pythonライブラリを用いたWebスクレイピングコードを実装します。
スクレイピングコード作成までの流れや工程ごとに考えることなど解説します。
最終的に、クラウドソーシングサイトなどのリスト作成案件のレベルを理解できます。
また、筆者自身クラウドソーシングサイトであるランサーズにてコンスタントに毎月10万円を稼ぎ、スクレイピング業務にて2021年6月に最高報酬額である30万円を突破しました。
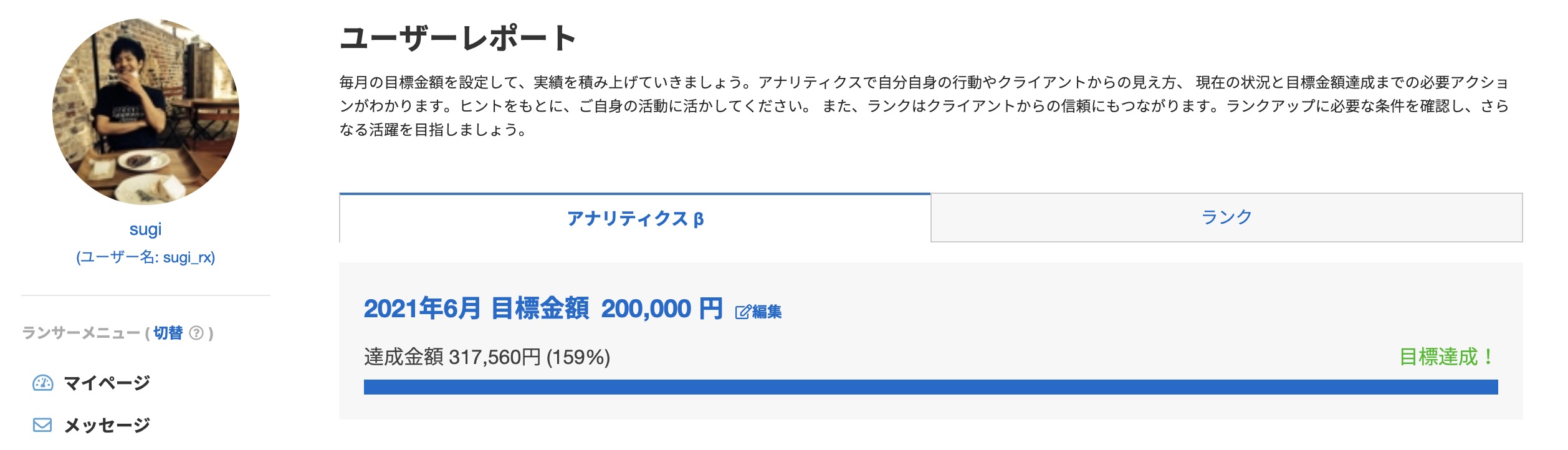
年間報酬額も100万円突破するなど、実務的なスクレイピング技術の活用方法や具体的な稼ぎ方について、一定の記事信頼を担保できると思います。
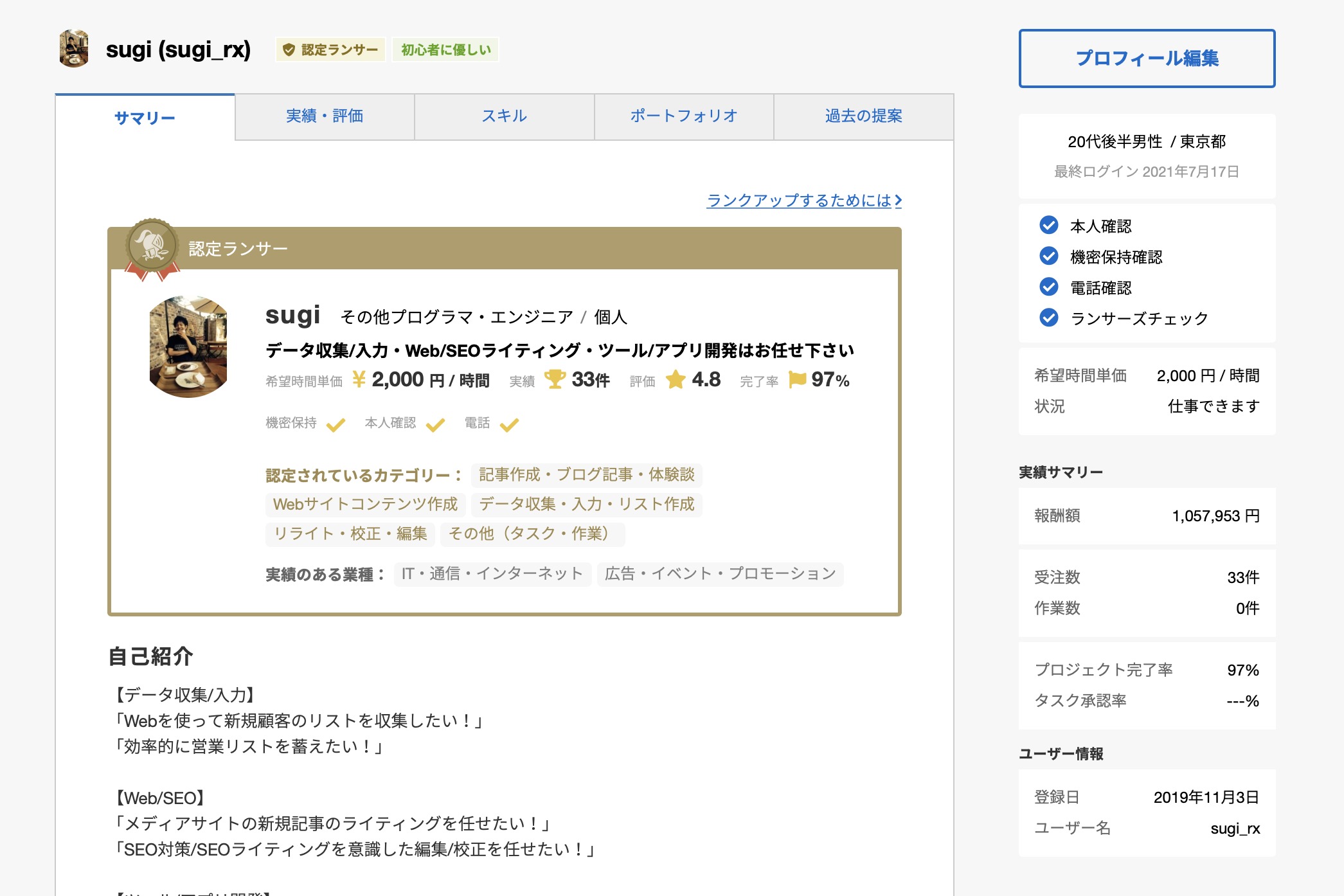
プログラミングの中でもスクレイピング技術は習得することで、副業に十分活かせる武器になると先にお伝えしておきます。
目次
スクレイピングコードが求められる案件
スクレイピングとは、特定のWebサイトにおけるページ情報を収集することです。
また、基本的にスクレイピングコードが求められる場面は以下のタイミングです。
|
スクレイピングが情報収集を目的とするため、特定サイトが案件ごとに変化するのが一般的です。
以下の画像は、クラウドソーシングサイトであるランサーズにて発注されていた案件です。
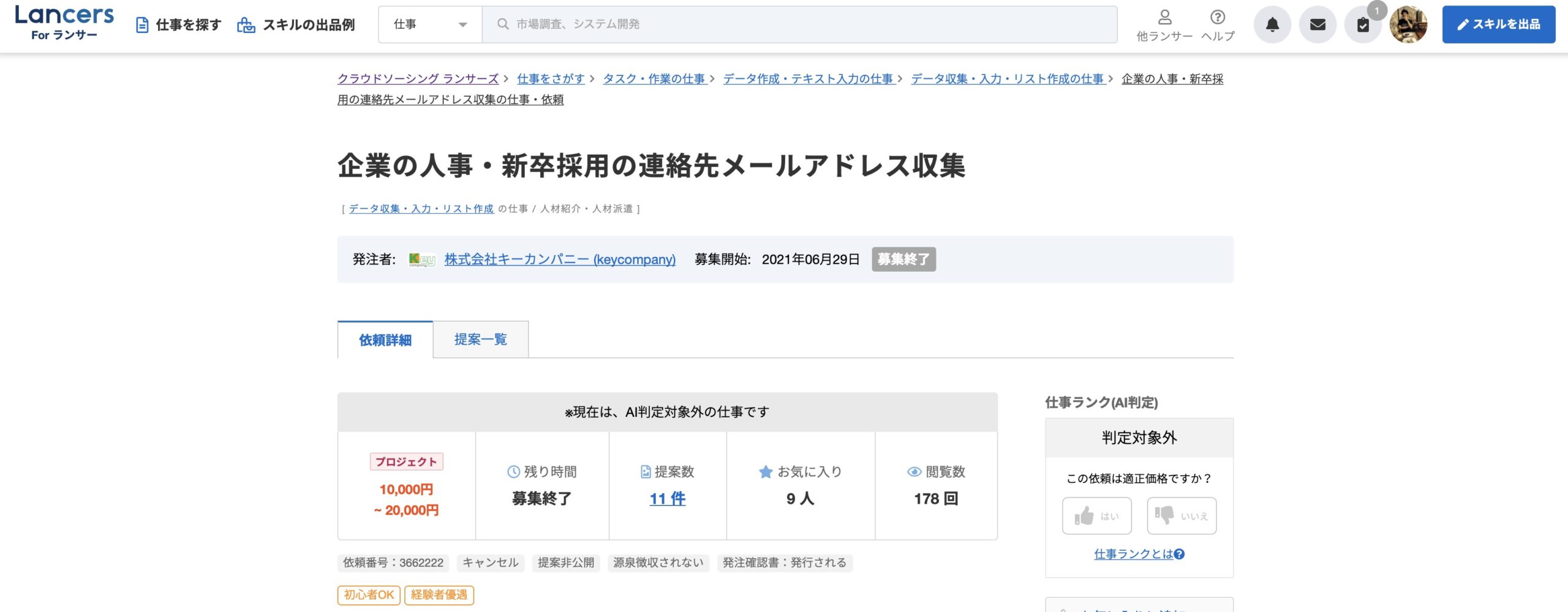

例として取り上げましたが、クラウドワークスやランサーズで「リスト作成」案件を探せば、類似案件は大量に発注されています。
本記事で取り扱うサンプルコードは、採用ホームページ・求人サイトどちらも関連する”マイナビ”を指定サイトとして作成しています。
スクレイピングの具体的な流れや必要となる知識を詳しく知りたい人は、「【python】スクレイピングで利用する各種ライブラリと稼ぐための活用方法」で解説します。

実践的なスクレイピングコード作成の流れ
”マイナビ”を指定サイトとした場合、以下の状況を確認する必要があります。
指定サイトが異なる場合でも、基本的に確認事項は変わらないと思います。
|
どんな指定サイトであっても、この流れは基本となります。
以下の項目は”マイナビ”を指定サイトとした場合、上記の確認事項を当てはめて具体化した流れです。
|
次章から具体的な流れを画像とコードを含めて解説します。
Seleniumによるスクレイピングの流れ
ここから任意の.pyファイルを作成してコードを実装します。
import time from datetime import timedelta from datetime import datetime as dt import requests, bs4 from bs4 import BeautifulSoup from selenium import webdriver import traceback import os import csv from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.chrome.options import Options
個人的に利用したいライブラリがいくつか存在したため、複数のライブラリをインポートしています。
特に、スクレイピングで利用するrequests、BeautifulSoup、SeleniumなどはPCにインストールしたのちにインポートします。
SeleniumはWebドライバーも必要になるため、適宜環境構築します。
#chromedriverの設定
options = Options()
#options.add_argument('--headless')
driver = webdriver.Chrome(r"driverのパス入力", chrome_options=options)次に、webdriverを利用するため、ドライバーのパスを入力してアクセスできる設定を施します。
#キーワード入力
search_word = input("業種キーワード=")
# 作成日のフォルダとファイル作成
today = dt.now()
tstr = today.strftime('%Y-%m-%d')
if os.path.exists(tstr) == False:
os.mkdir(tstr)
#csvファイル生成
with open(os.path.join(tstr, search_word + '.csv'),'w',newline='',encoding='utf8') as outcsv:
csvwriter = csv.writer(outcsv)
csvwriter.writerow(['会社名','住所','電話番号','メールアドレス'])
キーワード検索を用いて、ヒットさせたい企業を変更できるようコード実装しています。
また、ローカルPCにて作成日となるフォルダとCSVファイルを生成するコードも実装しています。
今回は、会社名・住所・電話番号・メールアドレスを取得します。
#マイナビ url = 'https://job.mynavi.jp/22/pc/corpinfo/searchCorpListByGenCond/index?actionMode=searchFw&srchWord=' + search_word + '&q=' + search_word + '&SC=corp' driver.get(url)
urlの変数にマイナビサイトのURLを指定します。
指定したURLに対して入力したキーワードを付与し、driver.get()にてサイトアクセスしブラウザを展開します。
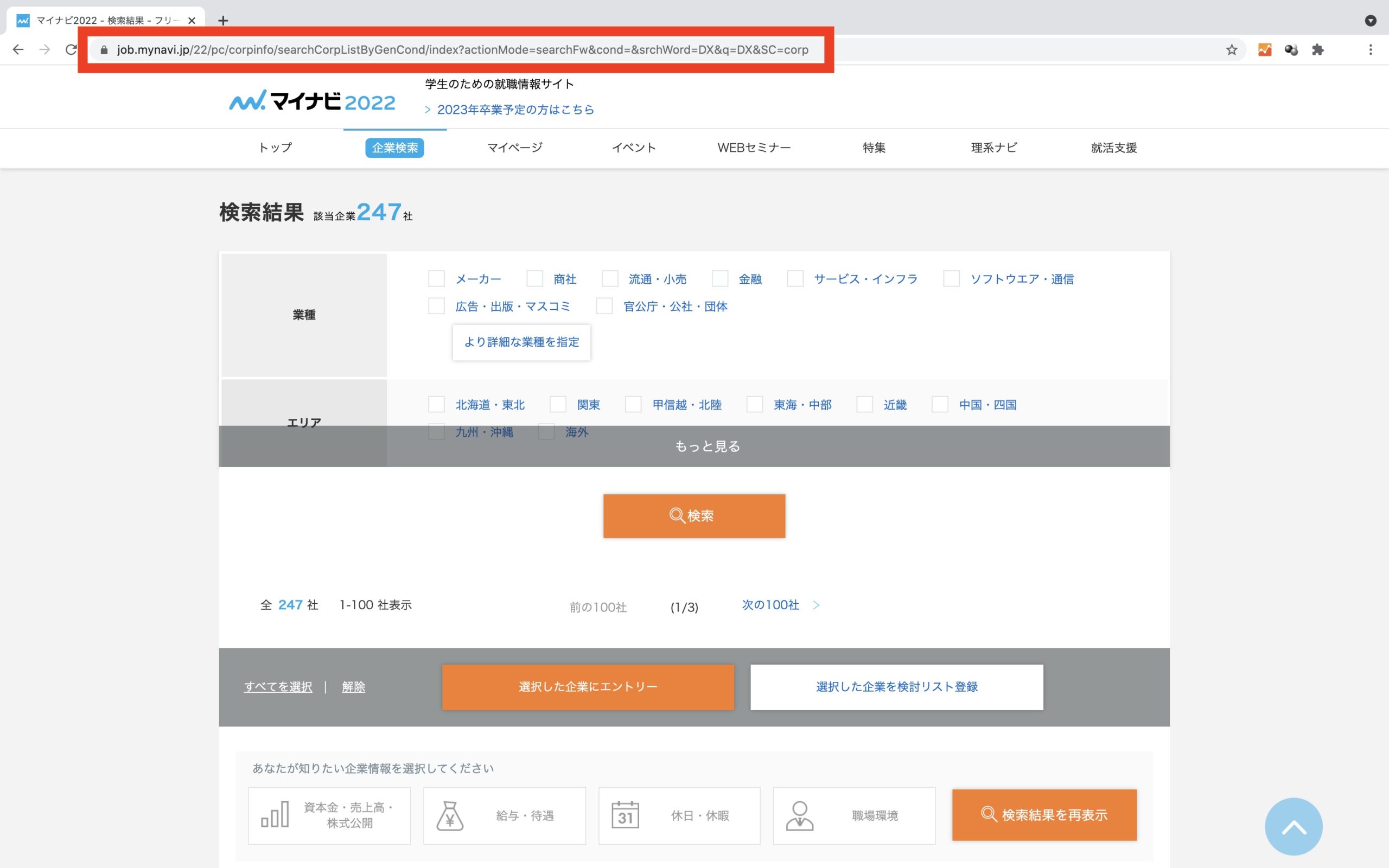
キーワードとして”DX”を指定しサイト内検索した企業一覧ページになります。
#企業詳細url格納リスト
com_urls = []
#企業の詳細urlの取得
while True:
i = 0
count = 0
error_flag = 0
wait = WebDriverWait(driver, 10)
com_list = wait.until(EC.visibility_of_all_elements_located((By.CLASS_NAME, 'boxSearchresultEach')))
count = len(com_list)
for lists in com_list:
com_url = lists.find_element_by_tag_name("a").get_attribute("href")
com_urls.append(com_url)
i = i + 1
try:
if i == count:
next_page = driver.find_element_by_xpath('//*[@id="upperNextPage"]').click()
time.sleep(3)
except:
traceback.print_exc()
error_flag = 1
if error_flag == 1:
break
driver.close()
検索結果の各企業詳細ページのURLを格納する変数を用意します。
wihle文にて、ページカウントを行いながら、リスト変数にクラス名’boxSearchresultEach’でヒットした値(各企業詳細ページのHTML要素)を取得します。
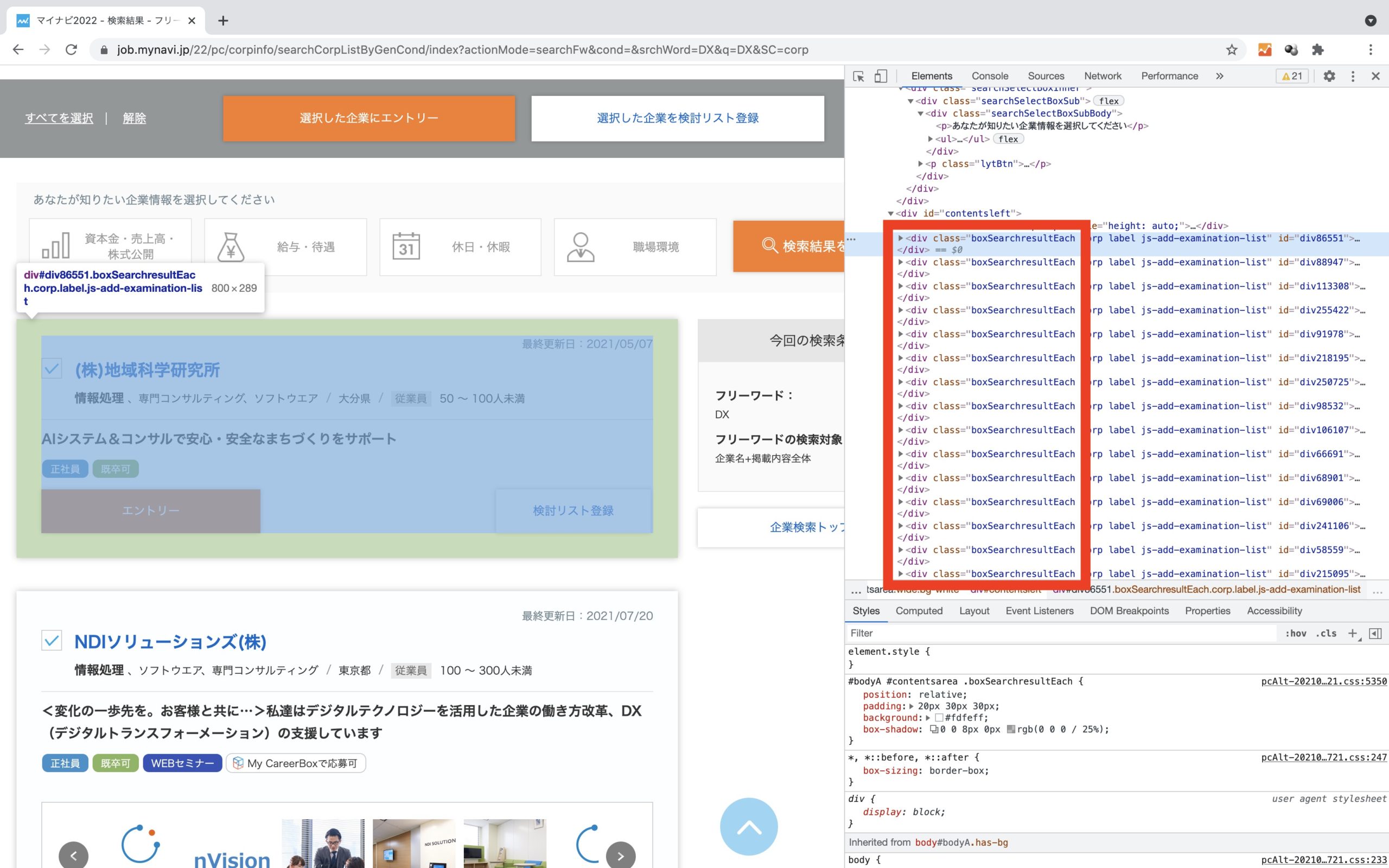
また、取得した各企業詳細ページのHTML要素内から、for文にて<a href>タグ要素のテキストデータであるURLを抽出します。

ページカウントと同様に、各企業詳細ページのHTML要素内のURL数もカウントし、i == count(マイナビでは100 == 100)となれば、次ページに遷移して処理を繰り返します。
イコールでなければ、企業一覧ページの企業数が100件未満であるため、1ページだけで処理を終えるよう実装しています。
seleniumのみで各企業の詳細ページへアクセスすると膨大なブラウザを展開する必要があるため、ここでは各企業詳細ページのURLを取得できたタイミングでdriver.close()し処理を終えています。
requests&BeautifulSoupによるスクレイピングの流れ
次に、seleniumにてスクレイピングした各企業詳細ページのURLを利用して詳細情報の特定と抽出を行い、CSVファイルに出力します。
for line in com_urls:
#レスポンスの確認
res = requests.get(line)
#解析
soup = bs4.BeautifulSoup(res.text, "html.parser")
try:
#企業の詳細リンクの取得
name = soup.select_one("#companyHead > div.heading1 > div > div > div.heading1-inner-left > h1").text
address = soup.select_one("#corpDescDtoListDescText50").text
number = soup.select_one("#corpDescDtoListDescText220").text
mail = soup.select_one("#corpDescDtoListDescText130").text
print(name,address,number,mail)
print('------------------------------------------------')
#csvファイルへの書き込み
with open(os.path.join(tstr, search_word + '.csv'),'a',newline='',encoding='utf8') as outcsv:
csvwriter = csv.writer(outcsv)
csvwriter.writerow([name, address, number, mail])
except:
traceback.print_exc()
print("next")for文にて、取得したURLの数だけ同じ繰り返し処理を行います。
requestsを利用して各取得URLにアクセスし、企業ページのテキストデータを取得します。
BeautifulSoupを用いて、取得した企業ページのテキストデータをHTML要素として解析(パース)します。
try-exceptを利用して、会社名・住所・電話番号・メールアドレスを特定/抽出し、全てのデータが満たされている場合にCSVファイルに出力します。
データが満たされていない場合は、何が取得できていないかエラーを吐き出し、繰り返し処理を実行します。
name = soup.select_one("#companyHead > div.heading1 > div > div > div.heading1-inner-left > h1").text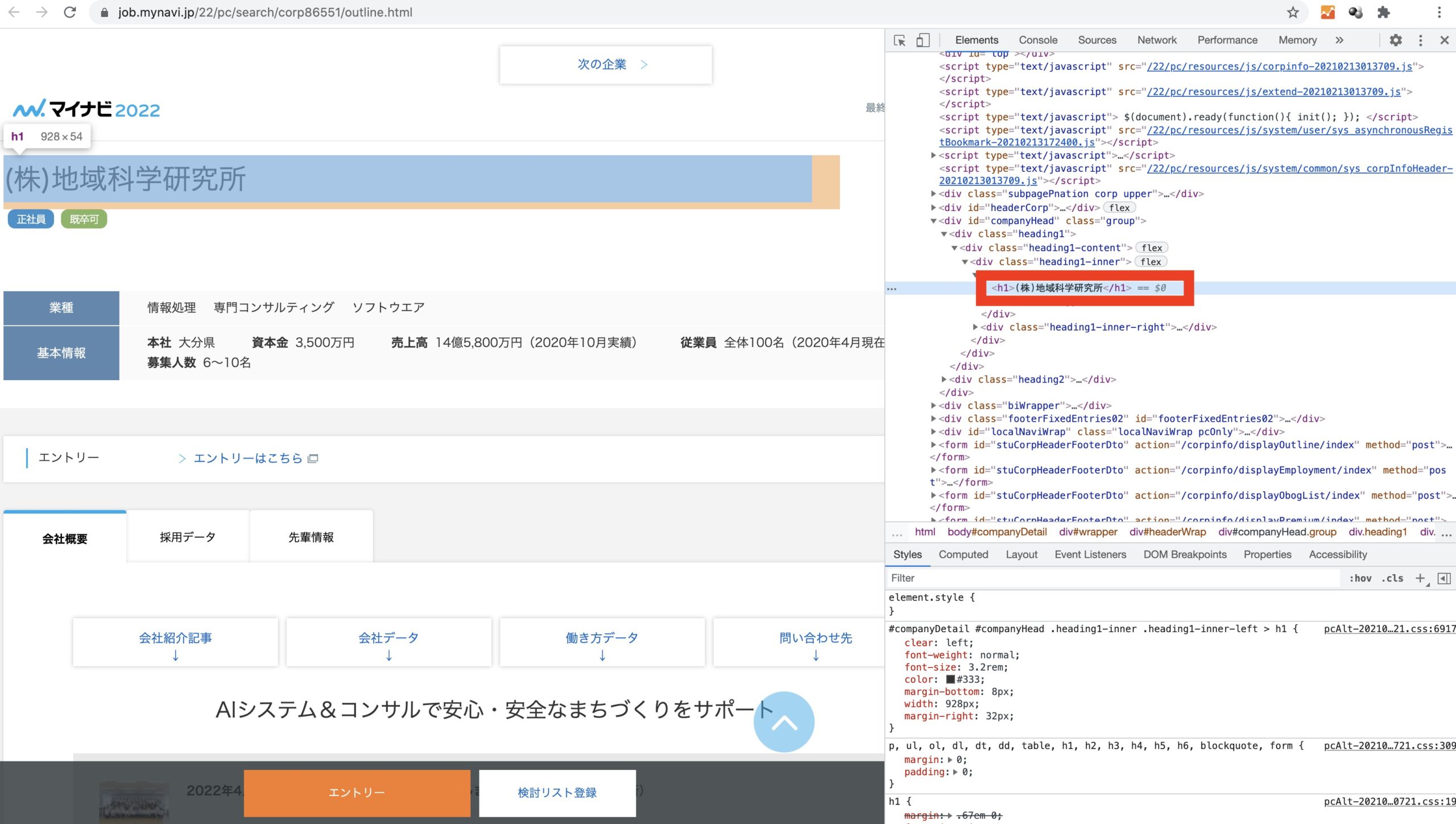
BeautifulSoupのselect_oneメソッドを利用して、企業詳細ページのHTML要素から会社名を抽出しています。
address = soup.select_one("#corpDescDtoListDescText50").text
number = soup.select_one("#corpDescDtoListDescText220").text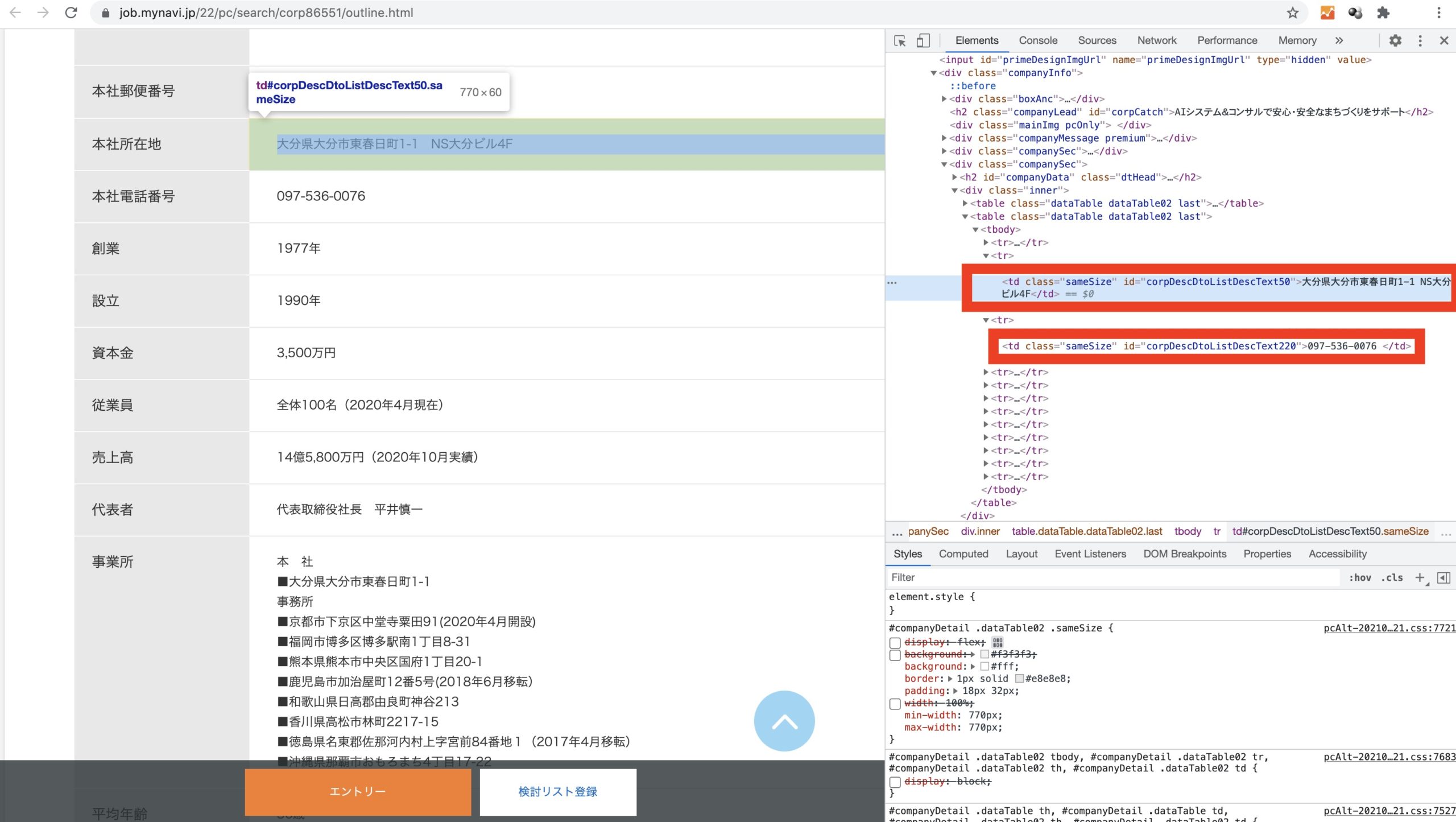
BeautifulSoupのselect_oneメソッドを利用して、企業詳細ページのHTML要素から住所と電話番号を抽出しています。
mail = soup.select_one("#corpDescDtoListDescText130").text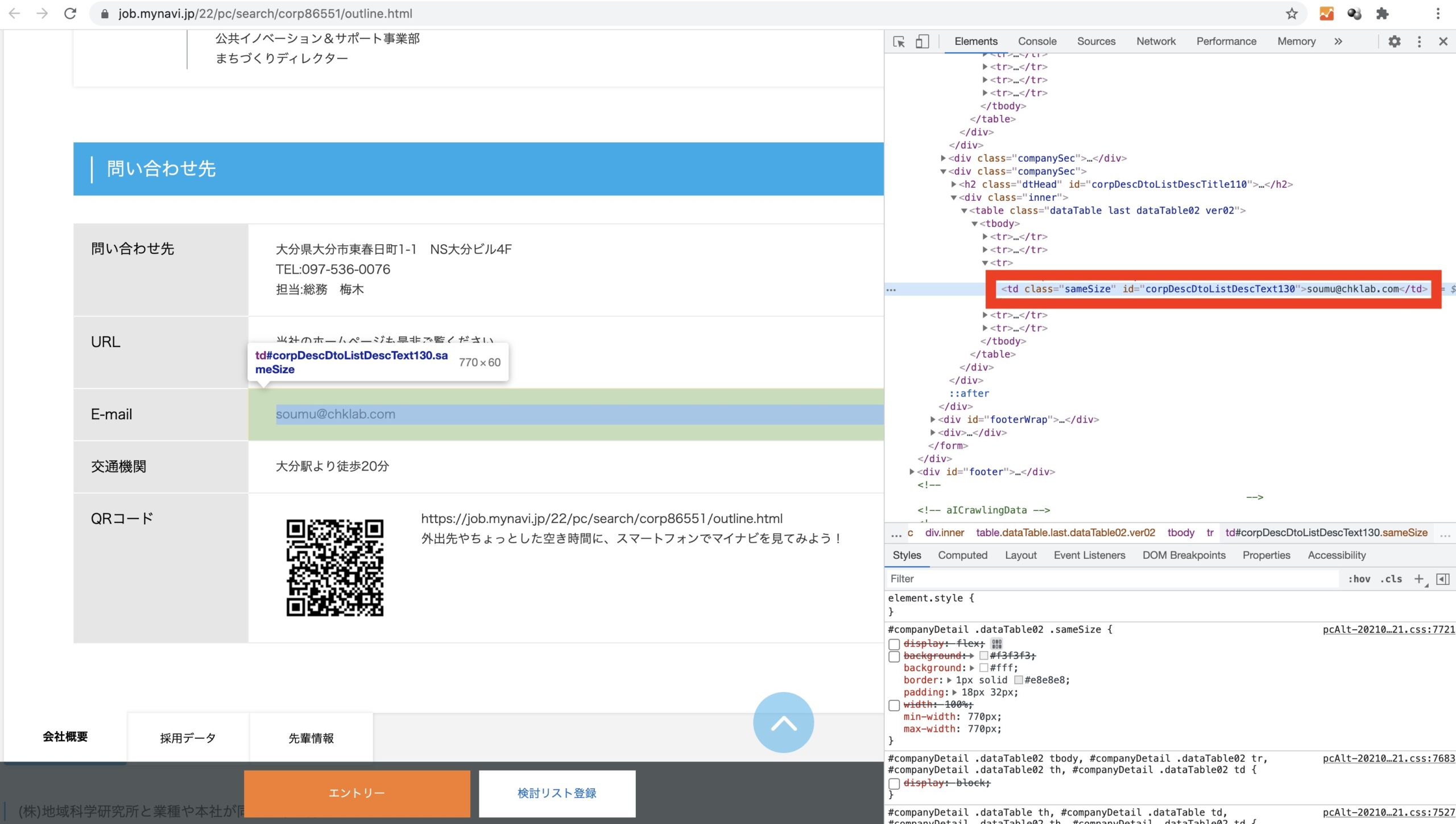
BeautifulSoupのselect_oneメソッドを利用して、企業詳細ページのHTML要素からメールアドレスを抽出しています。
最終的に、with open関数を利用して抽出したデータ群をCSVファイルに書き込み、取得したURLの件数分を繰り返します。
pythonによるスクレイピングサンプルコードの全体像
以下がスクレイピングサンプルコードの全体像になります。
import time
from datetime import timedelta
from datetime import datetime as dt
import requests, bs4
from bs4 import BeautifulSoup
from selenium import webdriver
import traceback
import os
import csv
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
#chromedriverの設定
options = Options()
#options.add_argument('--headless')
driver = webdriver.Chrome(r"driverのパス入力", chrome_options=options)
#キーワード入力
search_word = input("業種キーワード=")
# 作成日のフォルダとファイル作成
today = dt.now()
tstr = today.strftime('%Y-%m-%d')
if os.path.exists(tstr) == False:
os.mkdir(tstr)
#csvファイル生成
with open(os.path.join(tstr, search_word + '.csv'),'w',newline='',encoding='utf8') as outcsv:
csvwriter = csv.writer(outcsv)
csvwriter.writerow(['会社名','住所','電話番号','メールアドレス'])
#マイナビ
url = 'https://job.mynavi.jp/22/pc/corpinfo/searchCorpListByGenCond/index?actionMode=searchFw&srchWord=' + search_word + '&q=' + search_word + '&SC=corp'
driver.get(url)
#企業詳細url格納リスト
com_urls = []
#企業の詳細urlの取得
while True:
i = 0
count = 0
error_flag = 0
wait = WebDriverWait(driver, 10)
com_list = wait.until(EC.visibility_of_all_elements_located((By.CLASS_NAME, 'boxSearchresultEach')))
count = len(com_list)
for lists in com_list:
com_url = lists.find_element_by_tag_name("a").get_attribute("href")
com_urls.append(com_url)
i = i + 1
try:
if i == count:
next_page = driver.find_element_by_xpath('//*[@id="upperNextPage"]').click()
time.sleep(3)
except:
traceback.print_exc()
error_flag = 1
if error_flag == 1:
break
driver.close()
for line in com_urls:
#レスポンスの確認
res = requests.get(line)
#解析
soup = bs4.BeautifulSoup(res.text, "html.parser")
try:
#企業の詳細リンクの取得
name = soup.select_one("#companyHead > div.heading1 > div > div > div.heading1-inner-left > h1").text
address = soup.select_one("#corpDescDtoListDescText50").text
number = soup.select_one("#corpDescDtoListDescText220").text
mail = soup.select_one("#corpDescDtoListDescText130").text
print(name,address,number,mail)
print('------------------------------------------------')
#csvファイルへの書き込み
with open(os.path.join(tstr, search_word + '.csv'),'a',newline='',encoding='utf8') as outcsv:
csvwriter = csv.writer(outcsv)
csvwriter.writerow([name, address, number, mail])
except:
traceback.print_exc()
print("next")全体から理解するのは難しいですが、一つ一つを分離しながら取り組むことで全体像が把握でき理解しやすくなります。
また、スクレイピングで利用するSelenium、requests、BeautifulSoupの特徴を活かすことで簡単かつ効率的にデータ収集できます。
ぜひ、サンプルコードを変更して別の特定サイトでもスクレイピング実行してみてください。
pythonによるスクレイピングサンプルコードの実行結果
以下の画像がサンプルコードの実行結果で得られたCSVファイルになります。
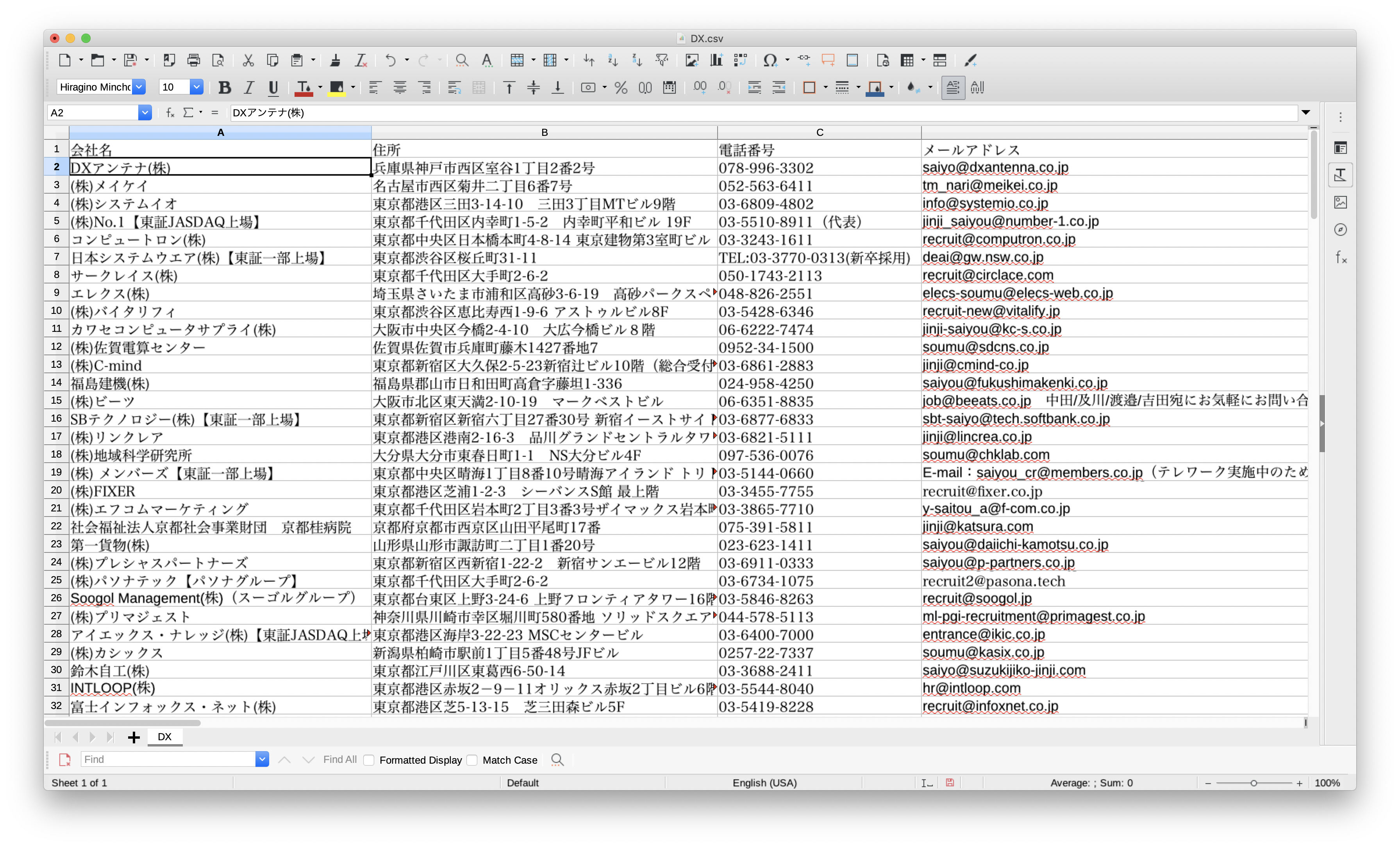
サンプルコードでは、会社名・住所・電話番号・メールアドレスの4つのデータが満たされているデータのみCSVファイルに出力されます。
そのため、キーワード”DX”にて取得できた企業データは、合計で177件(マイナビ2022より)になりました。
まとめ
スクレイピングとは、特定のWebサイトにおけるページ情報を収集することです。
また、基本的にスクレイピングコードが求められる場面は以下のタイミングです。
|
スクレイピングが情報収集を目的とするため、特定サイトが案件ごとに変化するのが一般的です。
pythonによるスクレイピングを実行する場合、抽象的なスクレイピングの流れからイメージしましょう。
|
基本的にどんな指定サイトでも操作は変わりません。
また、今回はマイナビサイトを利用しましたが、抽象的な流れを把握できたら具体的なスクレイピングの流れを構想しましょう。
|
具体的なスクレイピングの流れを構想できたら、スクレイピングコードの実装になります。
プログラミングコードは、具体的な処理の流れが把握/理解できなければコードに落とし込むことができません。
抽象的な流れ→具体的な流れ→コード実装といった作業を想定しておきましょう。
python初心者でも実現可能なプログラムは数多くあるため、python初心者が簡単に作成できるものを知りたい人は、「【認定ランサー】Python初心者が作れるものを目的別に学習方法解説!」で解説します。


























