
実は需要の高いプログラミングスキルの中に、外部機能を利用するための仕組みとしてAPI技術が存在します。
『TwitterやYouTubeでよく聞くAPIってなに?』
『APIが利用できると何が実現できるの?』
『APIが使えると結局稼ぐことができるの?』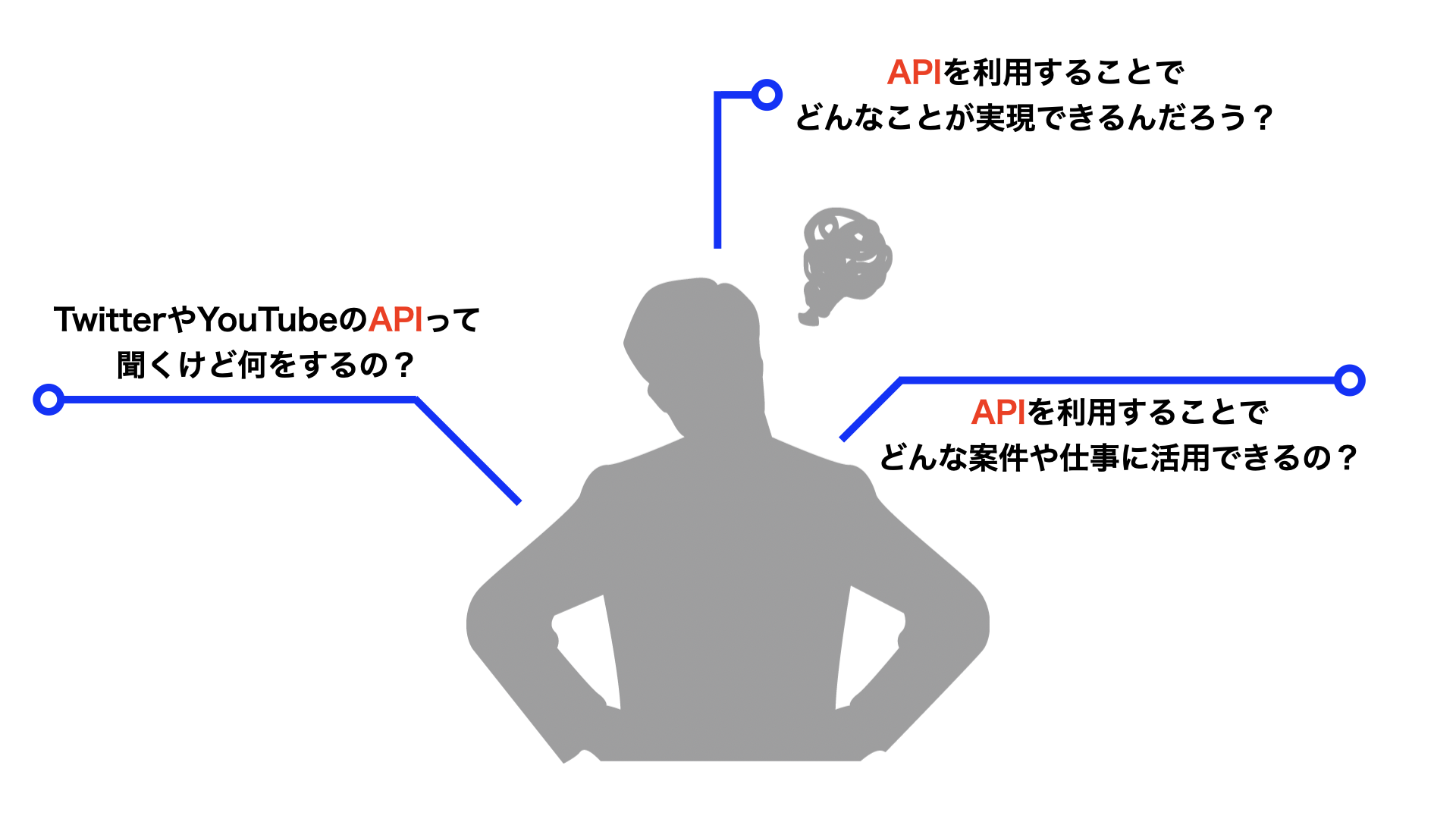 このような疑問や悩みを解決した記事構成になっています。
このような疑問や悩みを解決した記事構成になっています。
そして本記事では、様々なAPIの中でも人気が高まってきているYouTube Data API v3を利用していきたいと思います。
また、クラウドソーシングサービスであるクラウドワークスやランサーズの案件も確認しながら、取り進めていきます。
また、筆者自身クラウドソーシングサイトであるランサーズにてコンスタントに毎月10万円を稼ぎ、プログラミング業務にて2021年6月に最高報酬額である30万円を突破しました。
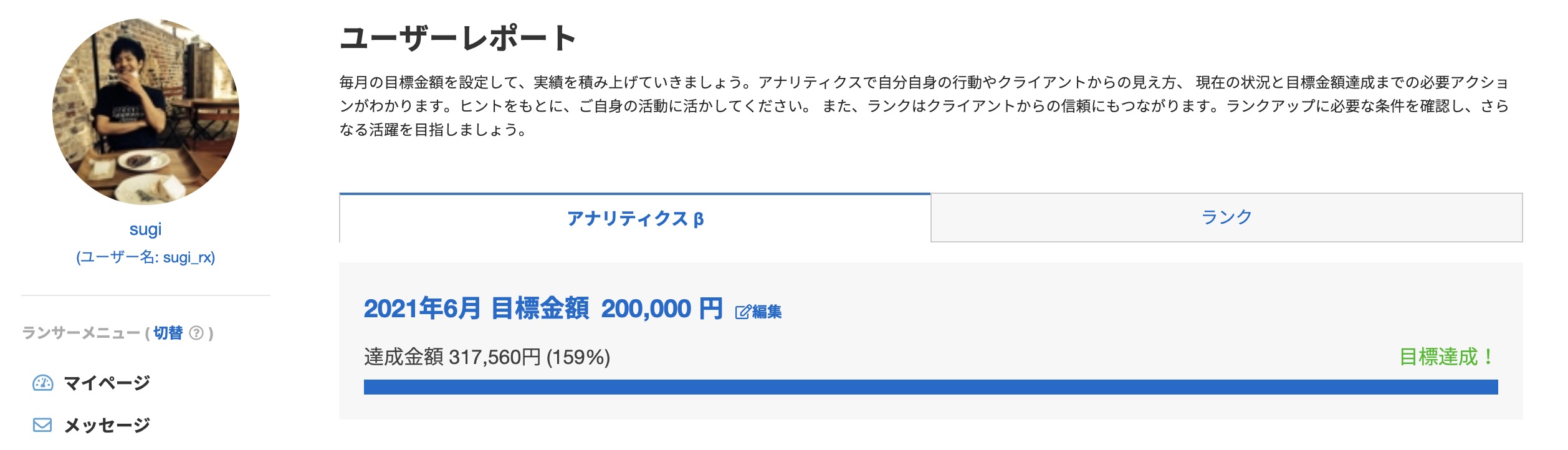
年間報酬額も100万円突破するなど、実務的なプログラミングの活用方法や具体的な稼ぎ方について、一定の記事信頼を担保できると思います。
プログラミングは習得することで、本業/副業に十分活かせる武器になると先にお伝えしておきます。
目次
YouTube APIの種類
YouTube APIはGoogle社が提供しているAPIになります。
また、YouTubeに関して提供されているAPIの種類は、以下の4つです。
|
また、本記事のメインではYouTube Data API v3にて、YouTubeチャンネル情報/各動画データ情報の取得方法を解説しています。
<API – Application Programming Interfaceとは>
第三者が開発したアプリケーションに対して、機能を共有する意味を指します。
YouTube Data API v3の概要
YouTube Data API v3におけるリソースの種類は、以下の内容です。
|
上記の種類以外にも追加されているリソースが存在するため、別の種類も確認したい人はYouTube Data APIリファレンスを参照してください。
YouTube Data API v3を利用した主な案件
クラウドワークス・ランサーズどちらにおいても、YouTube Data API v3を利用した案件が多く見受けられます。
実際の依頼内容が記載されているものを画像として貼っておきます。
<1件目>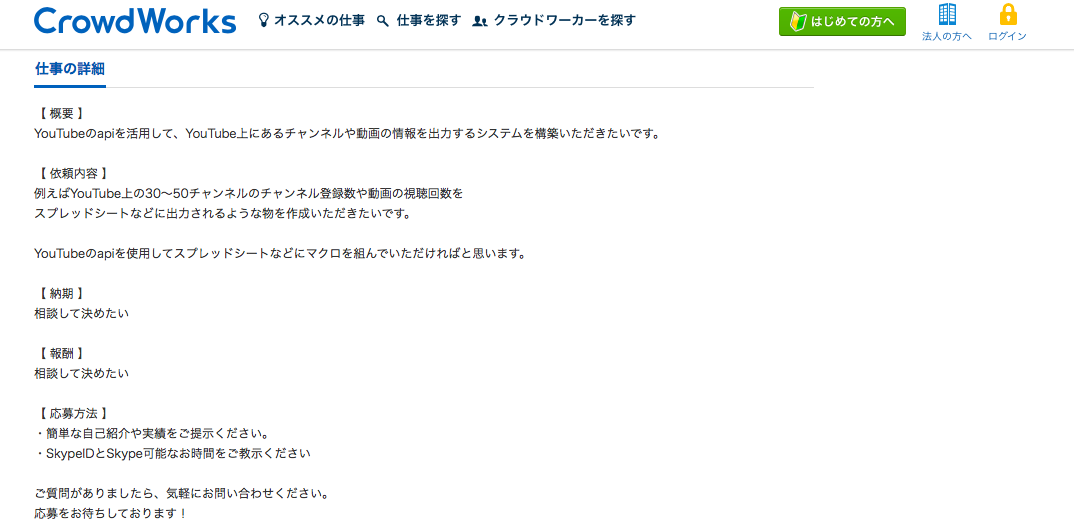 <2件目>
<2件目>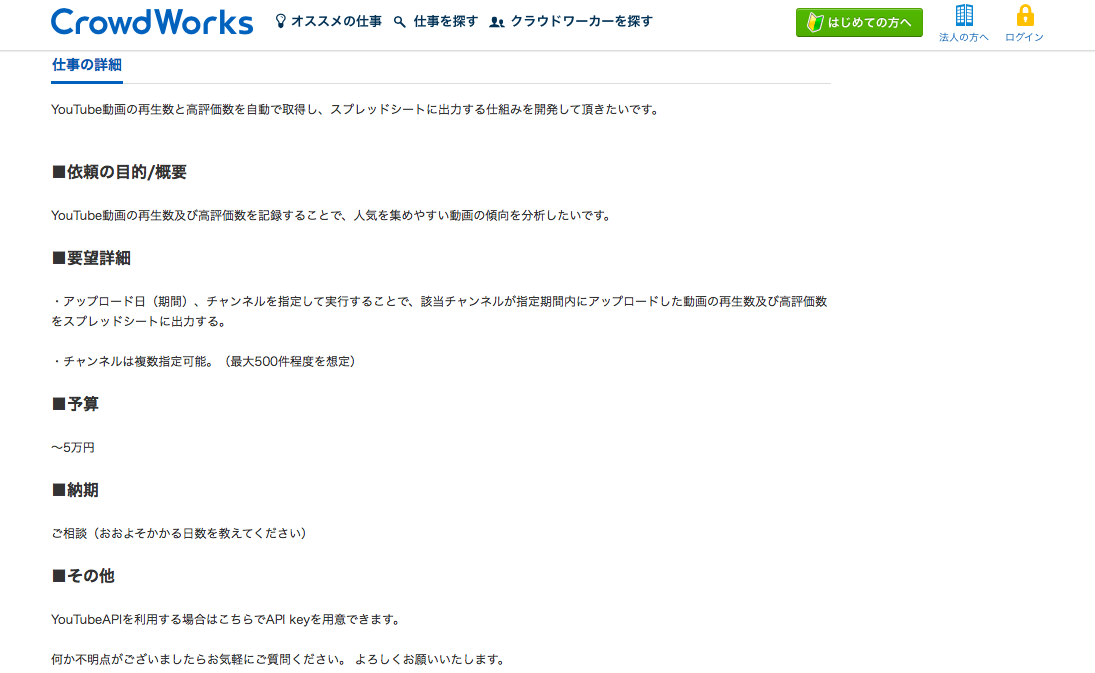 <3件目>
<3件目>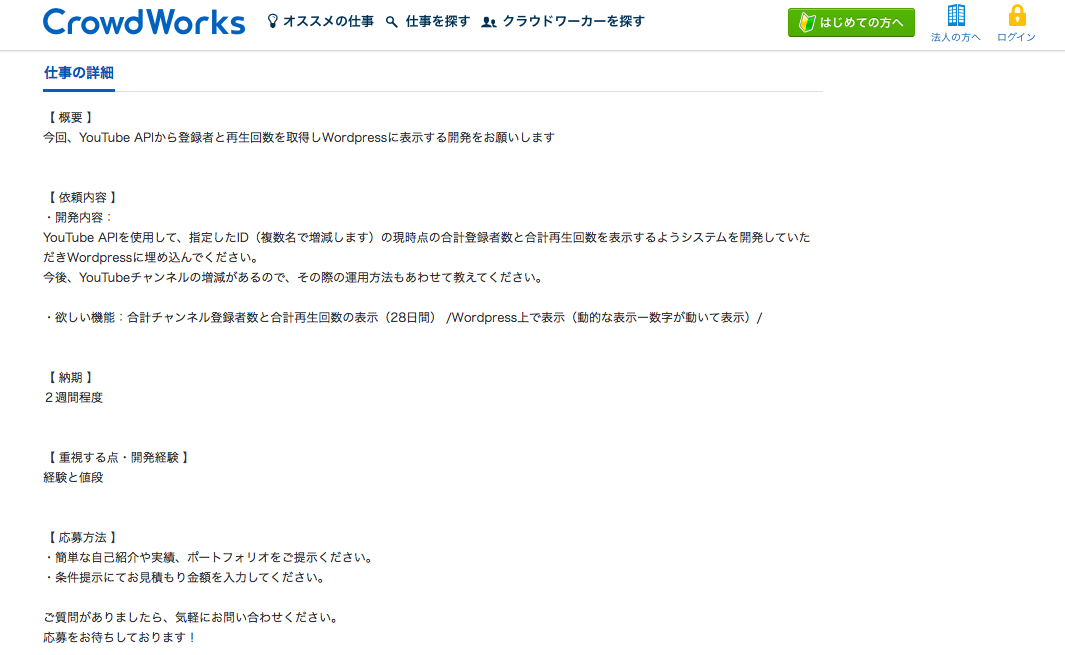 <4件目>
<4件目>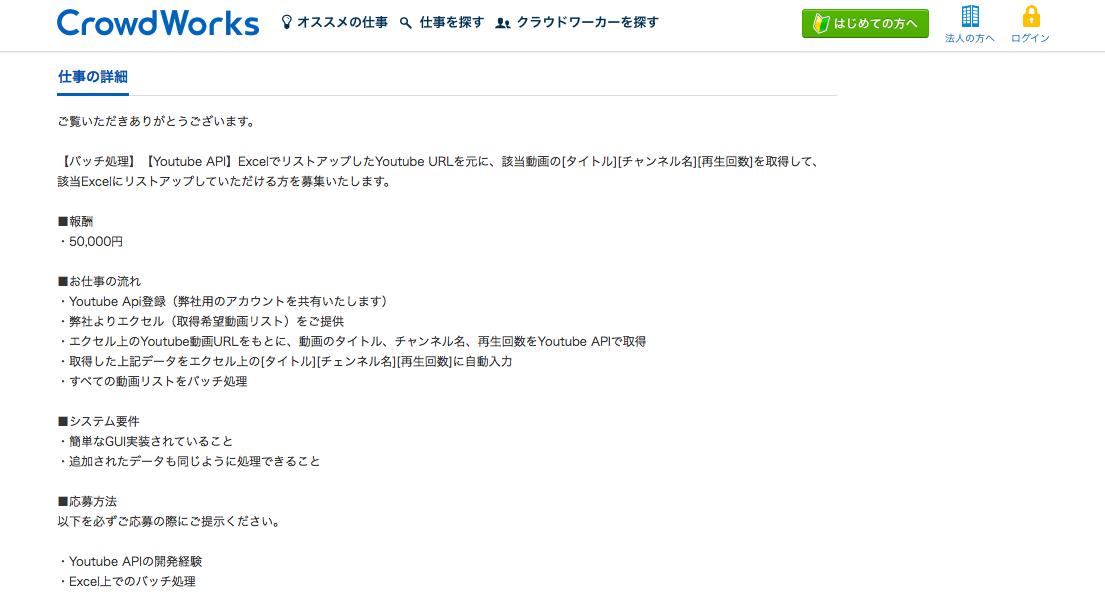 <5件目>
<5件目>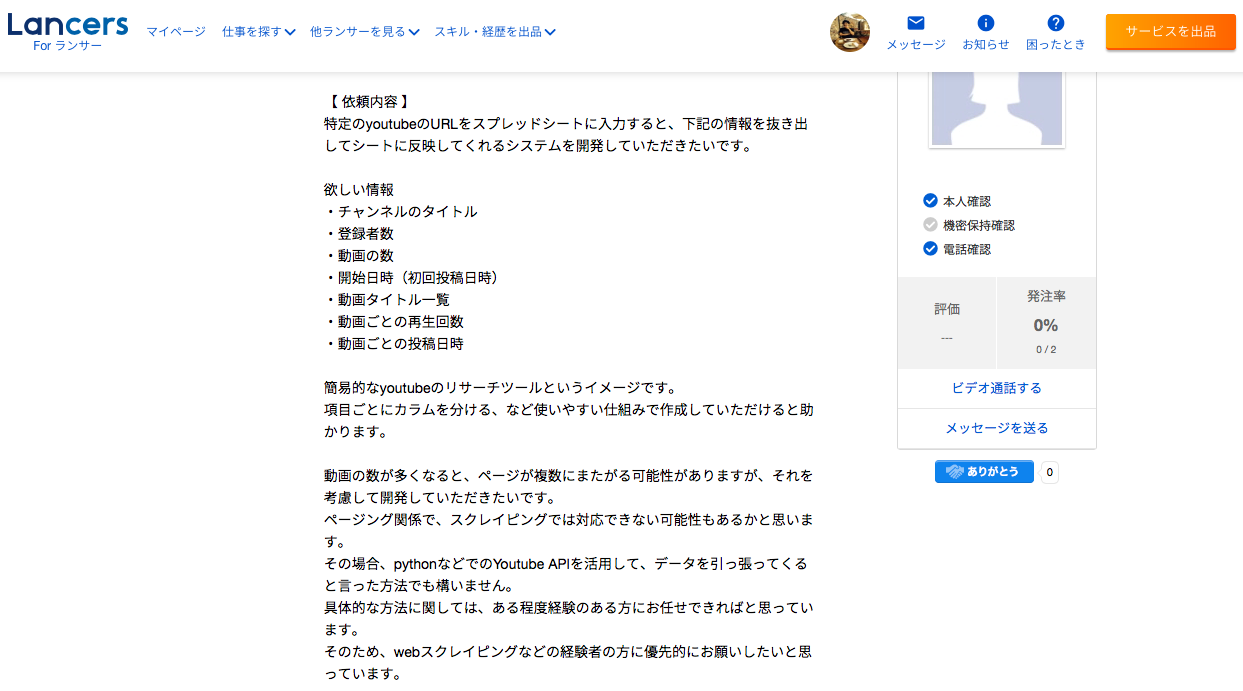
かつてここまで案件画像を貼った記憶がないので、やはりYouTube関連の案件が多くなってきたことが頷けるかと思います。
また、案件報酬を調査していると、一番安い報酬で5000円、一番高い報酬だと30万円、平均的に見れば5万円程度といったところでしょうか。
どの案件も共通するのは、特定チャンネルの動画情報取得がメインになりそうです。
|
GCP(Google Cloud Platform)にて、YouTube Data API v3のAPI Key取得から行なっていきます。
次にPython言語を利用して、はじめに特定チャンネルのChannel IDを取得します。
今度はChannel IDを利用して特定チャンネルの各種データ(チャンネルタイトル、登録者数、動画本数、開始日時)を取得し、チャンネル用csvファイルを出力します。
さらに同様のChannel IDを利用して、特定チャンネルから投稿されている各動画からVideo IDを取得し、その各動画のVideo IDに紐づく各種データ(動画タイトル、再生数、高評価、低評価、コメント数、投稿日時)を抜き出し、ビデオ用csvファイルを出力します。
このような流れで取り組んでみたいと思います。
YouTube Data API連携したFlaskによる簡易的な動画データ分析アプリを開発しました。

PythonでのWebアプリ開発に興味がある人は「【Python】Flask+YouTube Data APIによる動画データ分析アプリ開発」で解説します。

YouTube Data API v3のAPI Keyの取得
GCP(Google Cloud Platform)を利用したことがない人もいるかもしれないので、初めての人でも触れられるように解説していきたいと思います。
Cloud Consoleにアクセスしてください。
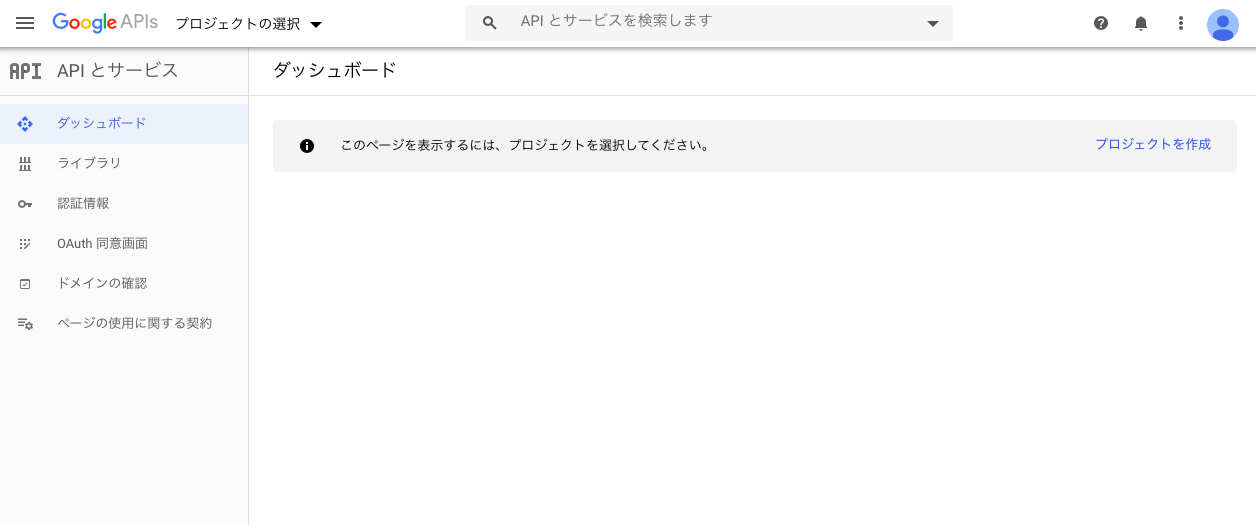
次に、『プロジェクトを作成』を押してください。
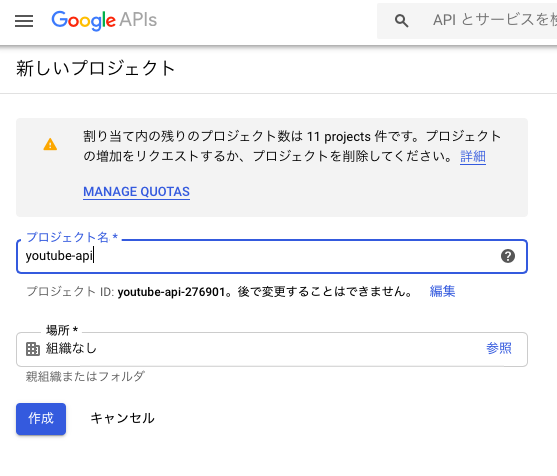
このようにプロジェクト名の入力を行う必要があるので、任意のプロジェクト名を入力して作成ボタンを押してください。
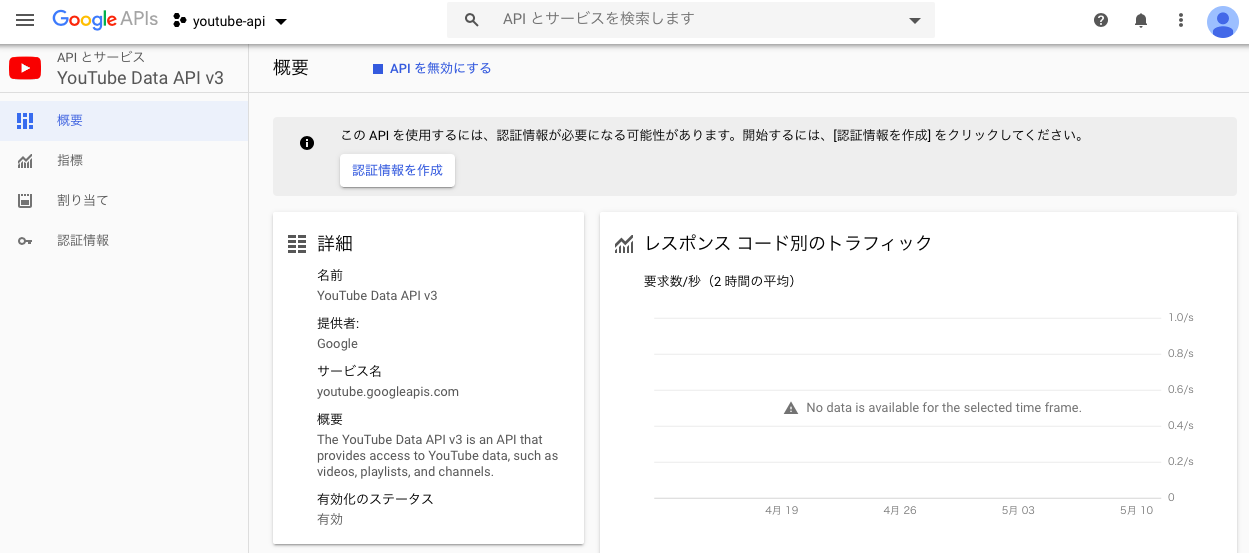
プロジェクトが作成できたら、もう一度APIライブラリからYouTube Data API v3を選択し、『認証情報を作成』ボタンをクリックします。
|
これらを選択したのちに、『必要な認証情報』ボタンをクリックすれば、API Keyが発行されるので、ここまででYouTube Data API v3のAPI Key取得の完了です。
特定チャンネルのChannel ID取得
おそらく数分程度でYouTube Data API v3のAPI Keyは取得できたかと思いますので、早速Pythonを利用して特定チャンネルのChannel IDを取得していきましょう。
from apiclient.discovery import build # API情報 API_KEY = 'YOUR_API_KEY' YOUTUBE_API_SERVICE_NAME = 'youtube' YOUTUBE_API_VERSION = 'v3' youtube = build( YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=API_KEY )
まずはじめに任意の.pyファイルを作成し、apiclientが利用できるようモジュールをインポートします。
コマンドプロンプトあるいはターミナルからインストールできるので、pip installを利用してモジュールをインストールしておいてください。
pip install --upgrade google-api-python-client
次に、取得したAPI Key等の情報を使って、外部機能の仕組みであるAPIを利用し変数youtubeを準備しておきます。
search_response = youtube.search().list(
q='[キーワード]',
part='id,snippet',
maxResults=25
).execute()
channels = []
for search_result in search_response.get("items", []):
if search_result["id"]["kind"] == "youtube#channel":
channels.append([search_result["snippet"]["title"],
search_result["id"]["channelId"]])
for channel in channels:
print(channel)次に、変数search_responseにあなたが決めた任意のキーワードを入力して、検索できる状態にしておきます。
今回は、リストとしてchannelsを用意してみました。
サブチャンネルなども取得できるので、網羅性を考慮してmaxResultsは25の設定でいきます。
実際にキーワード検索にて取得できたデータからチャンネル名とChannel IDを取得し、channelsに格納していきます。
これはあくまで特定チャンネルのChannel IDもYouTube Data API v3にて取得できないか模索した結果、このような形になりました。
改めて、特定チャンネルのChannel ID取得コードの全体像になります。
from apiclient.discovery import build
# API情報
API_KEY = 'YOUR_API_KEY'
YOUTUBE_API_SERVICE_NAME = 'youtube'
YOUTUBE_API_VERSION = 'v3'
youtube = build(
YOUTUBE_API_SERVICE_NAME,
YOUTUBE_API_VERSION,
developerKey=API_KEY
)
search_response = youtube.search().list(
q='[キーワード]',
part='id,snippet',
maxResults=25
).execute()
channels = []
for search_result in search_response.get("items", []):
if search_result["id"]["kind"] == "youtube#channel":
channels.append([search_result["snippet"]["title"],
search_result["id"]["channelId"]])
for channel in channels:
print(channel)プログラムを実行してみると、以下の結果が得られると思います。
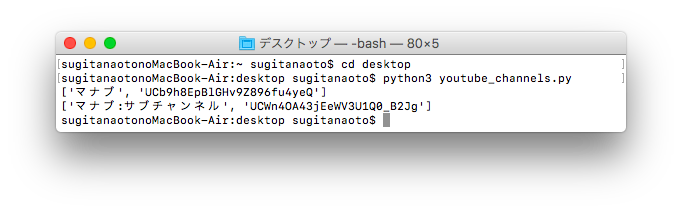 今回は、ブログやプログラミング等で多くの収益化を実現している”マナブ”さんをキーワードに取得してみました。
今回は、ブログやプログラミング等で多くの収益化を実現している”マナブ”さんをキーワードに取得してみました。
そして、このアルファベットと数字の羅列になっているものがChannel IDであり、これを以下の章でも利用していきます。
特定チャンネルの各種データ取得
Channel ID取得では別の.pyファイルを用いて、特定チャンネルの各種データ取得を行うので、あらためて新規ファイルを作成してください。
もしも一括で作りたい場合は、同じファイルでも構いません。
import pandas as pd from apiclient.discovery import build from apiclient.errors import HttpError API_KEY = 'YOUR_API_KEY' YOUTUBE_API_SERVICE_NAME = 'youtube' YOUTUBE_API_VERSION = 'v3' CHANNEL_ID = 'CHANNEL_ID' channels = [] #チャンネル情報を格納する配列 searches = [] #videoidを格納する配列 videos = [] #各動画情報を格納する配列 nextPagetoken = None nextpagetoken = None youtube = build( YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=API_KEY )
今回のファイルも同様にapiclientのモジュールをインポートしますが、合わせてcsvファイルを作成・出力するので、pandasもインポートしておきます。
こちらもAPI Keyを入力しますが、先ほど取得しておいた特定チャンネルのChannel IDも変数に格納しておきます。
また、必要に応じて各変数を用意しています。
channel_response = youtube.channels().list(
part = 'snippet,statistics',
id = CHANNEL_ID
).execute()
for channel_result in channel_response.get("items", []):
if channel_result["kind"] == "youtube#channel":
channels.append([channel_result["snippet"]["title"],channel_result["statistics"]["subscriberCount"],channel_result["statistics"]["videoCount"],channel_result["snippet"]["publishedAt"]])次に、googleが提供しているapiclientに含まれるchannels().list()を利用して、特定チャンネルの各種データを取得していきます。
膨大な量の情報が書き込まれているので、その中からチャンネルタイトル、登録者数、動画総数、開始日時を抜き出し、リスト変数channelsに格納しておきます。
特定チャンネルに紐づく各動画の各種データ取得
次に、重要になる特定チャンネルに紐づく各動画の各種データを取得していきますが、その前に各動画のVideo IDを全て取得していきます。
while True:
if nextPagetoken != None:
nextpagetoken = nextPagetoken
search_response = youtube.search().list(
part = "snippet",
channelId = CHANNEL_ID,
maxResults = 50,
order = "date", #日付順にソート
pageToken = nextpagetoken #再帰的に指定
).execute()
for search_result in search_response.get("items", []):
if search_result["id"]["kind"] == "youtube#video":
searches.append(search_result["id"]["videoId"])
try:
nextPagetoken = search_response["nextPageToken"]
except:
breakapiclientに含まれるsearch().list()を利用して、各動画のVideo IDを取得しますが、一度に50件までしか取得できません。
そのため、nextPagetokenと呼ばれる次ページの要素を取得し、再帰的にデータを取得し続けるようにしてあります。
各動画のVideo IDは、リスト変数searchesに格納していき、nextPagetokenが存在しないときループ処理を終了させています。
for result in searches:
video_response = youtube.videos().list(
part = 'snippet,statistics',
id = result
).execute()
for video_result in video_response.get("items", []):
if video_result["kind"] == "youtube#video":
videos.append([video_result["snippet"]["title"],video_result["statistics"]["viewCount"],video_result["statistics"]["likeCount"],video_result["statistics"]["dislikeCount"],video_result["statistics"]["commentCount"],video_result["snippet"]["publishedAt"]])ここでは、各動画のVideo IDを持つリスト変数searchesの中身を一つずつぶん回して、Video IDに紐づく各種データ(動画タイトル、再生数、高評価、低評価、コメント数、投稿日時)をリスト変数videosに格納していきます。
チャンネル用・ビデオ用csvファイルの作成・出力
最後にチャンネル用・ビデオ用のcsvファイルについては、pandasを利用してDataFrameを作成し、csvファイルとして出力できるよう整形していきます。
videos_report = pd.DataFrame(videos, columns=['title', 'viewCount', 'likeCount', 'dislikeCount', 'commentCount', 'publishedAt'])
videos_report.to_csv("videos_report.csv", index=None)
channel_report = pd.DataFrame(channels, columns=['title', 'subscriberCount', 'videoCount', 'publishedAt'])
channel_report.to_csv("channels_report.csv", index=None)ここで、あらためて全体のコードを記載しておきます。
import pandas as pd
from apiclient.discovery import build
from apiclient.errors import HttpError
API_KEY = 'YOUR_API_KEY'
YOUTUBE_API_SERVICE_NAME = 'youtube'
YOUTUBE_API_VERSION = 'v3'
CHANNEL_ID = 'CHANNEL_ID'
channels = [] #チャンネル情報を格納する配列
searches = [] #videoidを格納する配列
videos = [] #各動画情報を格納する配列
nextPagetoken = None
nextpagetoken = None
youtube = build(
YOUTUBE_API_SERVICE_NAME,
YOUTUBE_API_VERSION,
developerKey=API_KEY
)
channel_response = youtube.channels().list(
part = 'snippet,statistics',
id = CHANNEL_ID
).execute()
for channel_result in channel_response.get("items", []):
if channel_result["kind"] == "youtube#channel":
channels.append([channel_result["snippet"]["title"],channel_result["statistics"]["subscriberCount"],channel_result["statistics"]["videoCount"],channel_result["snippet"]["publishedAt"]])
while True:
if nextPagetoken != None:
nextpagetoken = nextPagetoken
search_response = youtube.search().list(
part = "snippet",
channelId = CHANNEL_ID,
maxResults = 50,
order = "date", #日付順にソート
pageToken = nextpagetoken #再帰的に指定
).execute()
for search_result in search_response.get("items", []):
if search_result["id"]["kind"] == "youtube#video":
searches.append(search_result["id"]["videoId"])
try:
nextPagetoken = search_response["nextPageToken"]
except:
break
for result in searches:
video_response = youtube.videos().list(
part = 'snippet,statistics',
id = result
).execute()
for video_result in video_response.get("items", []):
if video_result["kind"] == "youtube#video":
videos.append([video_result["snippet"]["title"],video_result["statistics"]["viewCount"],video_result["statistics"]["likeCount"],video_result["statistics"]["dislikeCount"],video_result["statistics"]["commentCount"],video_result["snippet"]["publishedAt"]])
videos_report = pd.DataFrame(videos, columns=['title', 'viewCount', 'likeCount', 'dislikeCount', 'commentCount', 'publishedAt'])
videos_report.to_csv("videos_report.csv", index=None)
channel_report = pd.DataFrame(channels, columns=['title', 'subscriberCount', 'videoCount', 'publishedAt'])
channel_report.to_csv("channels_report.csv", index=None)これでコード記述は終了したので、実際に実行して出力したcsvファイルを確認していきましょう。
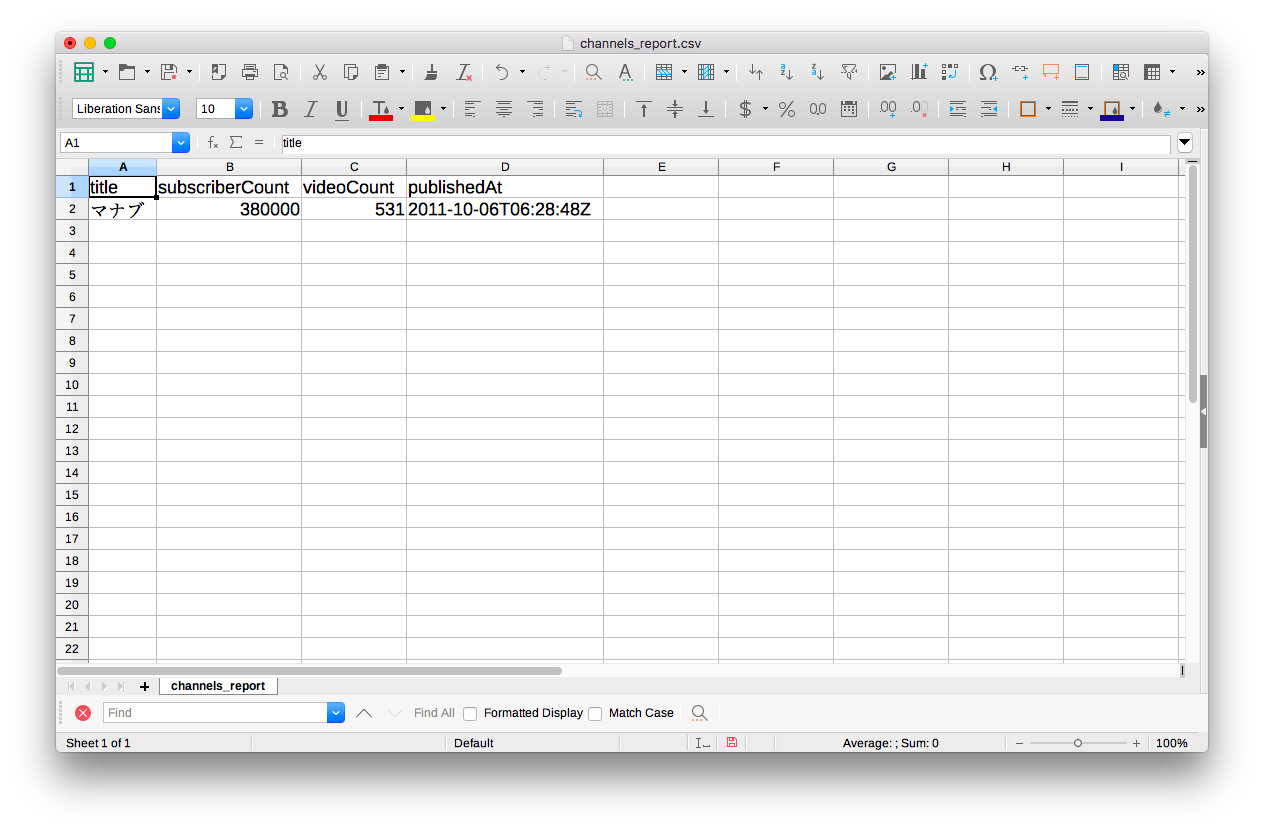 ちゃんと特定チャンネルのタイトル、登録者数、動画総数、開始日時が取得できていることがわかります。
ちゃんと特定チャンネルのタイトル、登録者数、動画総数、開始日時が取得できていることがわかります。

ビデオ用csvファイルにおいても、動画タイトル、再生数、高評価、低評価、コメント数、投稿日時を取得することができました。
YouTube Data API連携したFlaskによる動画データ分析アプリ開発
筆者が個人的にYouTube Data APIを連携させたFlaskによる簡易的な動画データ分析アプリを開発しました。

動画データ分析アプリでは、以下の開発工程を組んでいます。
|
全て工程ごとの作業とファイル構成/実装コードなど、画像とサンプルコードで解説しています。
Pythonを利用してFlask(フレームワーク)でアプリ開発してみたい人は「【Python】Flask+YouTube Data APIによる動画データ分析アプリ開発」を一読ください。
まとめ
実際の案件では、スプレッドシートとの連携等もありますが、メインとなるAPIの情報取得は無事完了することができました。
おそらく、このような動画の詳細データを利用して、競合分析を実施するためのツールとして求められているクライアントがいるようです。
最後に各動画データの情報取得が完了したので、項目ごとにソートして簡単なデータ分析をしていきましょう。
・再生数が多い順
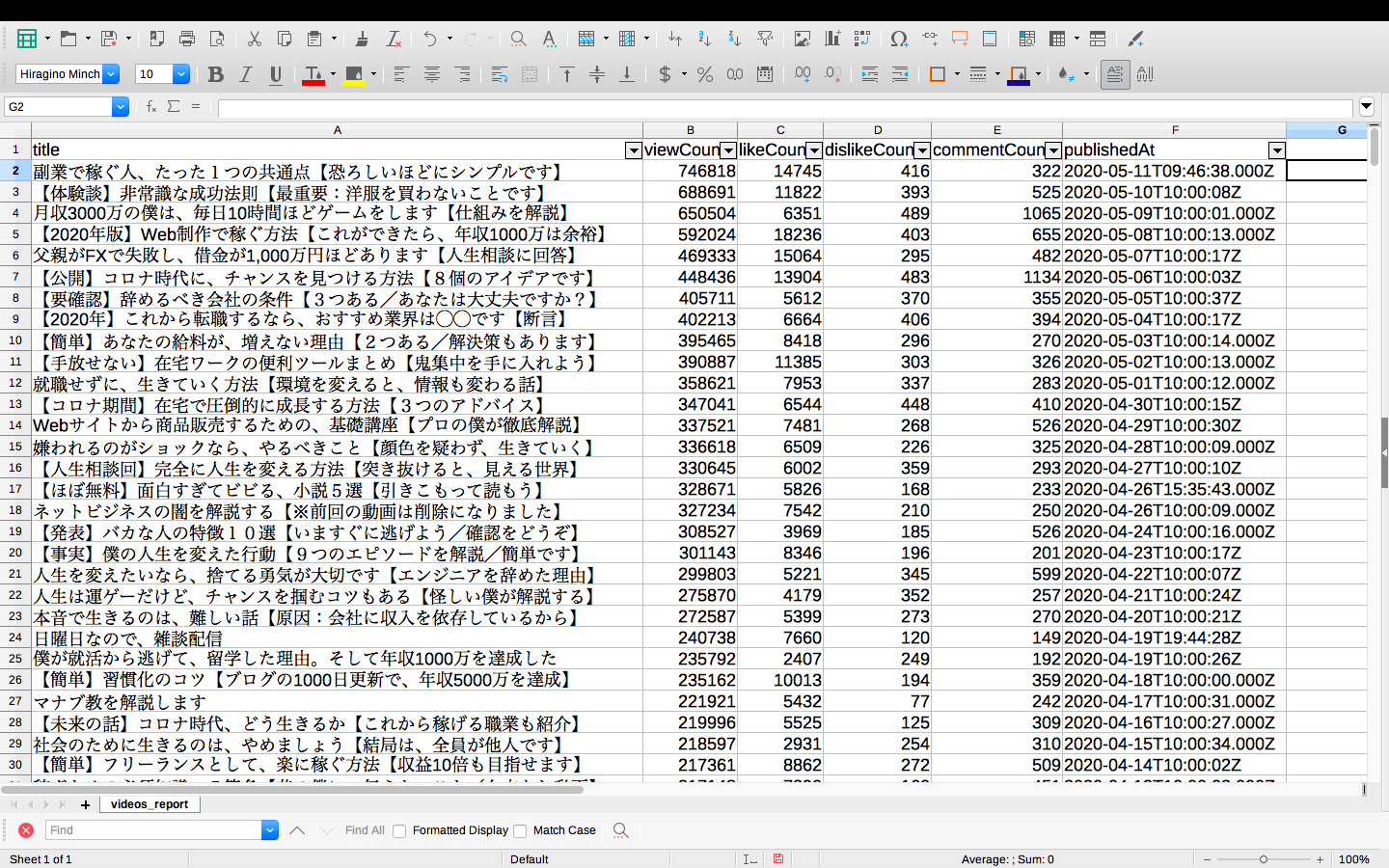
再生数を多い順にした結果、タイトルを確認するとお金にまつわる動画が集中していることがわかりました。
やはり時代的にも社会的にも稼ぐ力が求められているため、生活から切り離せない金銭関連動画が伸びてくるのでしょう。
特にブログ・プログラミング・YouTubeといった様々な分野で活躍しながら稼いでいる人なので、信用度も高いということでしょうか。
・高評価が多い順
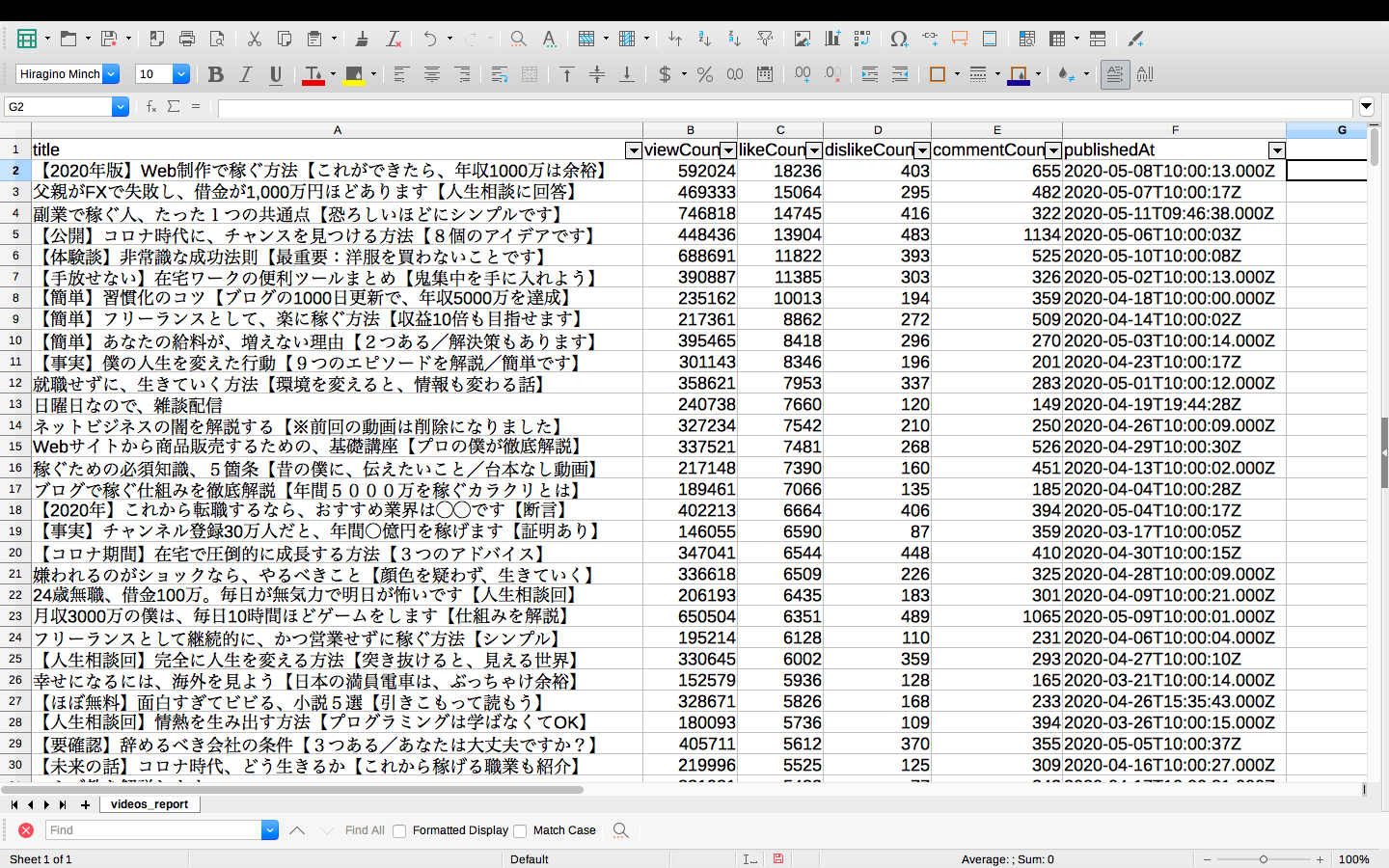
こちらも再生数と同様に、金銭関連動画が圧倒的に多いようです。
ただ、タイトルだけ見ていると月収や年収の単位・値が変動しまくっているので、どのタイミングで稼いでいたり、どのタイミングから収入何千万なのか、見分けがつかなくなってきますね笑
動画を観ないと天才ビジネスマンにしか見えません。
・低評価が多い順
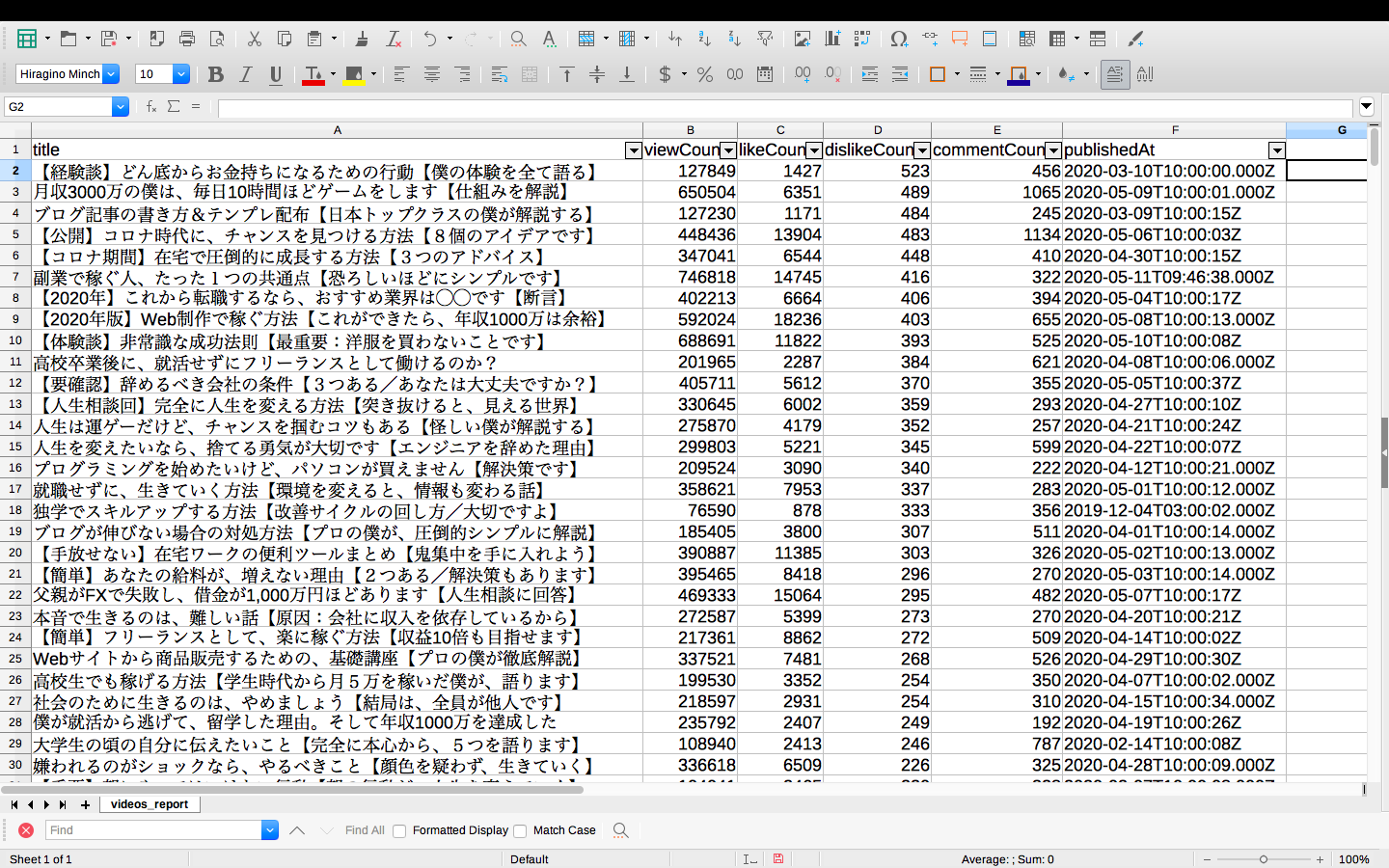
全てのパターンで共通していることは、マナブさんのデータは投稿日時が最新であるほど、基本的に再生数も高評価数も低評価数もコメント数も増加傾向にあることがわかってきました。
つまり、どんな形であれ着々と視聴者を作り出せているからこその数字の伸びだと思います。
・コメント数が多い順
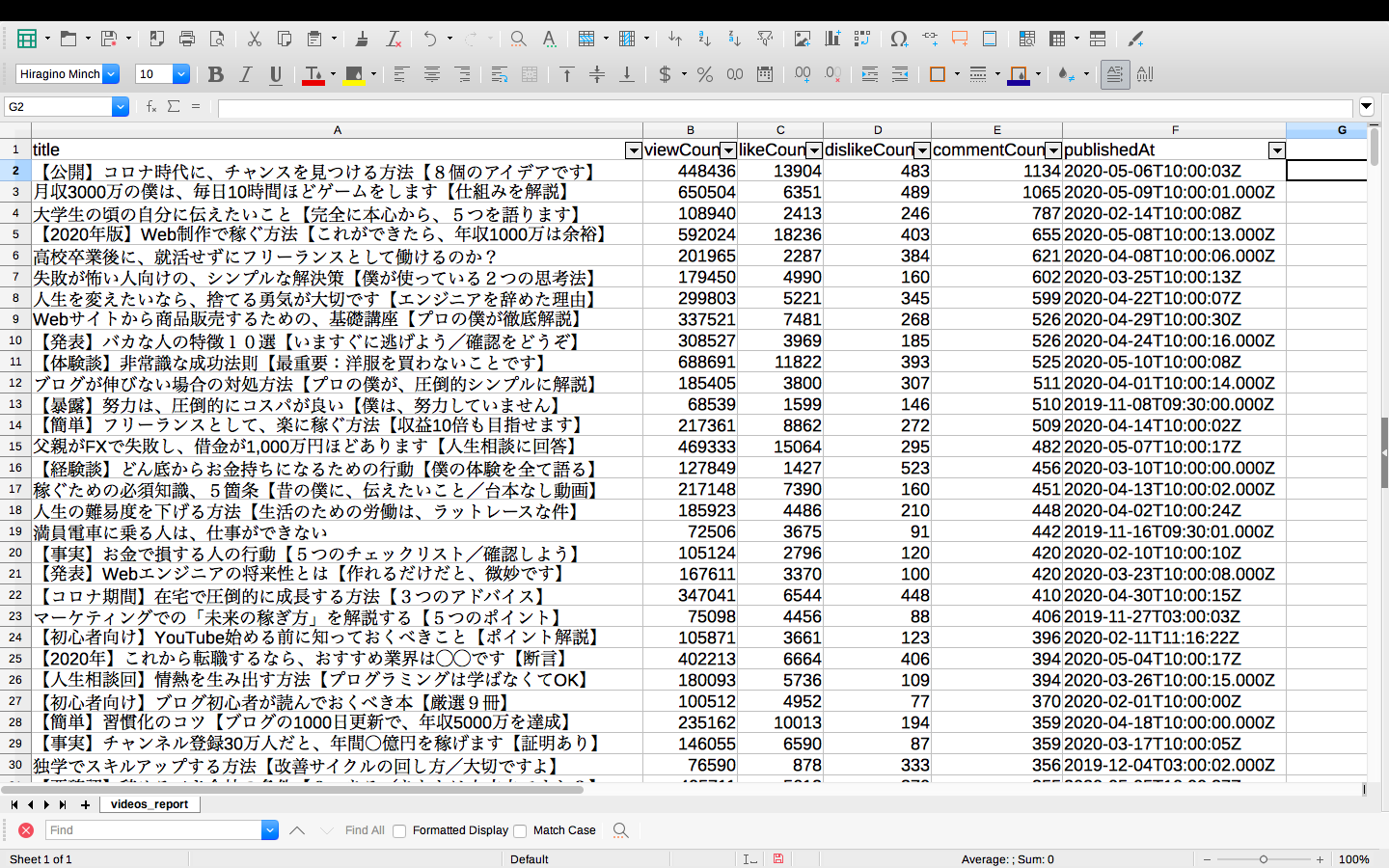
コメント数の多い順に並べてわかった結果は、やはり時代的な内容であれば反響も大きいということです。
コロナというキーワードは現在ビッグキーワードになっていそうですね。
また、面白いのがゲームが含まれるタイトル動画にコメント数が多かったことです。
これはマナブさんにしては珍しいからという反応なのか、ゲーム関連の視聴者を巻き込めたということなのか、実際のコメントを収集してテキストマイニングのユーザー属性や辞書を利用したポジネガ分析によってどちらの反応なのか確認すると面白そうだなと感じました。
機械学習でモデリング・グラフ化すると、様々な傾向分析を行えそうです。
このようにYouTube Data API v3だけでも、これだけの情報取得と分析をすることができ、面白そうな案件もたくさん転がっています。
APIというプログラミングスキルを身につけることで、収入を獲得することができるイメージがついたのなら幸いです。
興味があれば、ぜひ一度動作確認してみてください。
また、Twitter(@sugi_rx)やブログ等で反応・コメントをいただければ、別のAPIを利用した案件ベースのシミュレーション学習の一つとしてまだまだ記事を投稿しようと思います。
記事執筆のモチベーション維持に繋がるので、ぜひツイッターアカウントのフォローやブログのブックマークをしていただけると嬉しいです。
























