
目次
Word2Vecについて
この記事を読み進める前に、よりテキストマイニングの内容を理解したい方は、下記のURLにてチェックしてみてください。

「Word2Vec」とは、文章中の語句をベクトルに変換するツールです。単語同士の繋がりに基づいて単語同士の関係性をベクトル化するわけです。
ツール名通り、単語をベクトルとして表現することで、その単語の意味を捕らえる手法となります。つまり、語句と語句の類似度を測ることができるわけですね。
Gensimとインストールについて
Word2Vecを実現するツールとして、いくつか挙げられるライブラリがあります。
今回は、実行速度が速く、Pythonから手軽に利用できるものを考えると、「Gensim」ライブラリを使いたいと思います。この「Gensim」は、自然言語処理のためのライブラリです。
テキスト処理のための多くの機能を備えており、Word2Vec機能も備えています。「Gensim」はのインストールは、pipコマンド一発でインストール可能です。テキストマイニングを試しに行ってみたい方は利用してみてください。
以下にインストールのコマンドを記載します。
pip install gensim
モデル作成
今回は、model-making.pyとword2vec.pyの二つのファイルを作成します。
それぞれに行うプログラムを記載して説明していきます。
プログラムの概要
1 – model-making.py
■処理の流れ
1. python解析器janome,ベクトル変換ツールword2vecをインポート
2. 作成したテキストファイルの読み込み
3. 形態素解析
4. テキストを一行ごとに処理した内容を任意の品詞で抽出
5. 書き込み先のテキストを開く
6. word2vecでモデル作成
# python解析器janome, ベクトル変換ツールword2vecをインポート from janome.tokenizer import Tokenizer from gensim.models import word2vec import re
1では、今回のテキストマイニングに必要なライブラリとして、python解析器janomeとベクトル変換ツールword2vecをインポートします。
テキスト一行ごとに処理を行う(データクレンジング)ため、正規表現マッチング操作を提供しているreもついでにインポートしておきます。
# テキストファイルの読み込み - 2
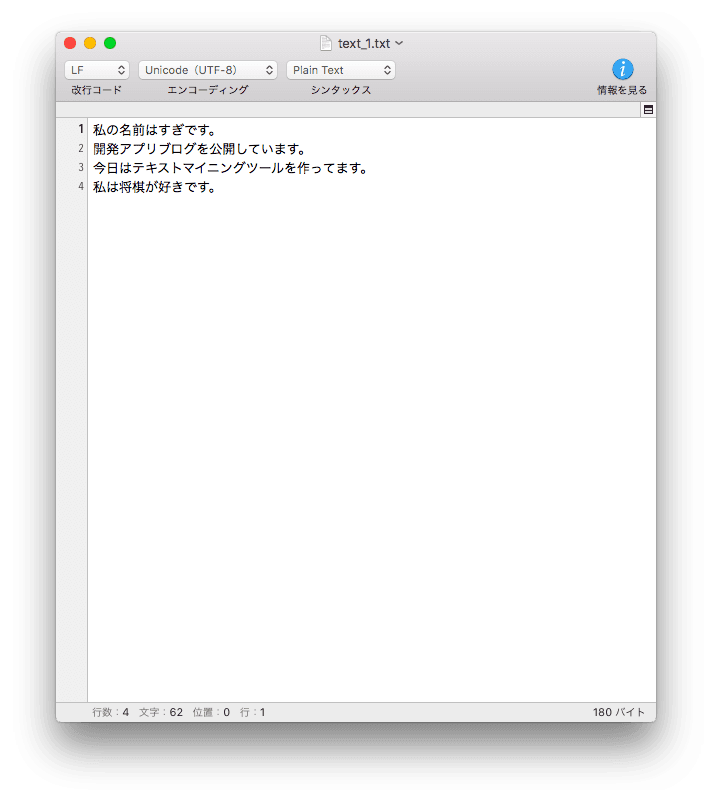
bindata = open("text_1.txt").read()
text = bindata
2では、任意で用意しておいたテキストファイル(何か文章を入力してあるファイル)を読み込みます。
# 形態素解析 - 3 t = Tokenizer() results = []
3では、janomeを利用して形態素解析を行うため、インスタンスを作成しておきます。
# テキストを一行ごとに処理 - 4
lines = text.split("\r\n")
for line in lines:
s = line
s = s.replace("|", "")
s = re.sub(r"《#.+?》", "", s)
s = re.sub(r"[#.+?]", "", s)
tokens = t.tokenize(s)
# 必要な語句だけを対象とする - 5
r = []
for tok in tokens:
if tok.base_form == "*":
w = tok.surface
else:
w = tok.base_form
ps = tok.part_of_speech
hinsi = ps.split(",")[0]
if hinsi in ["名詞", "形容詞", "動詞", "記号"]:
r.append(w)
rl = (" ".join(r)).strip()
results.append(rl)
print(rl)
4では、テキストを一行ごとに処理しています。
変数linesに対して、読み込んでおいたファイルデータをtextに代入し、その変数を単語ごとに処理しています。
forループにて、正規表現マッチング操作を行ったあと、一文字づつ形態素解析しています。
5では、得られた形態素解析後の単語の品詞を必要な形で分かち書きさせていきます。
# 書き込み先テキストを開く - 6
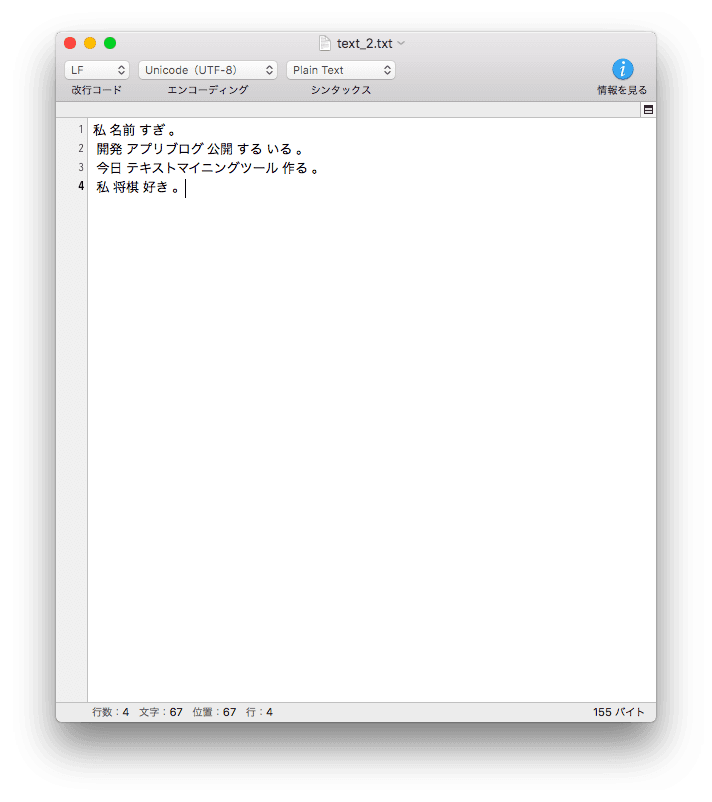
text_file = "text_2.txt"
with open(text_file, "w", encoding="utf-8") as fp:
fp.write("\n".join(results))
6では、用意しておいた任意のテキストファイルにて、結果をファイルに保存します。
# word2vecでモデル作成 - 7
data = word2vec.LineSentence(text_file)
model = word2vec.Word2Vec(data, size=100, window=1, hs=1, min_count=1, sg=1)
model.save("text_2.model")
print("ok")
7では、分かち書きしておいたテキストファイルを読み込み、word2vecにてモデルを作成します。word2vec()メソッドにてパラメータを与えて実行すると、モデルを生成します。生成したモデルは、save()メソッドにてファイルを保存できます。
★model-making★
# model_making.py
# python解析器janome, ベクトル変換ツールword2vecをインポート - 1
from janome.tokenizer import Tokenizer
from gensim.models import word2vec
import re
# テキストファイルの読み込み - 2
bindata = open("text_1.txt").read()
text = bindata
# 形態素解析 - 3
t = Tokenizer()
results = []
# テキストを一行ごとに処理 - 4
lines = text.split("\r\n")
for line in lines:
s = line
s = s.replace("|", "")
s = re.sub(r"《#.+?》", "", s)
s = re.sub(r"[#.+?]", "", s)
tokens = t.tokenize(s)
# 必要な語句だけを対象とする - 5
r = []
for tok in tokens:
if tok.base_form == "*":
w = tok.surface
else:
w = tok.base_form
ps = tok.part_of_speech
hinsi = ps.split(",")[0]
if hinsi in ["名詞", "形容詞", "動詞", "記号"]:
r.append(w)
rl = (" ".join(r)).strip()
results.append(rl)
print(rl)
# 書き込み先テキストを開く - 6
text_file = "text_2.txt"
with open(text_file, "w", encoding="utf-8") as fp:
fp.write("\n".join(results))
# word2vecでモデル作成 - 7
data = word2vec.LineSentence(text_file)
model = word2vec.Word2Vec(data, size=100, window=1, hs=1, min_count=1, sg=1)
model.save("text_2.model")
print("ok")
2 – word2vec.py
■処理の流れ
1. ベクトル変換ツールword2vecをインポート
2. 類似する語句を表示する
# ベクトル変換ツールword2vecをインポート from gensim.models import word2vec
1では、上記のファイルと同様、word2vecをインポートします。
# 類似する語句を表示 - 2
model = word2vec.Word2Vec.load("text_2.model")
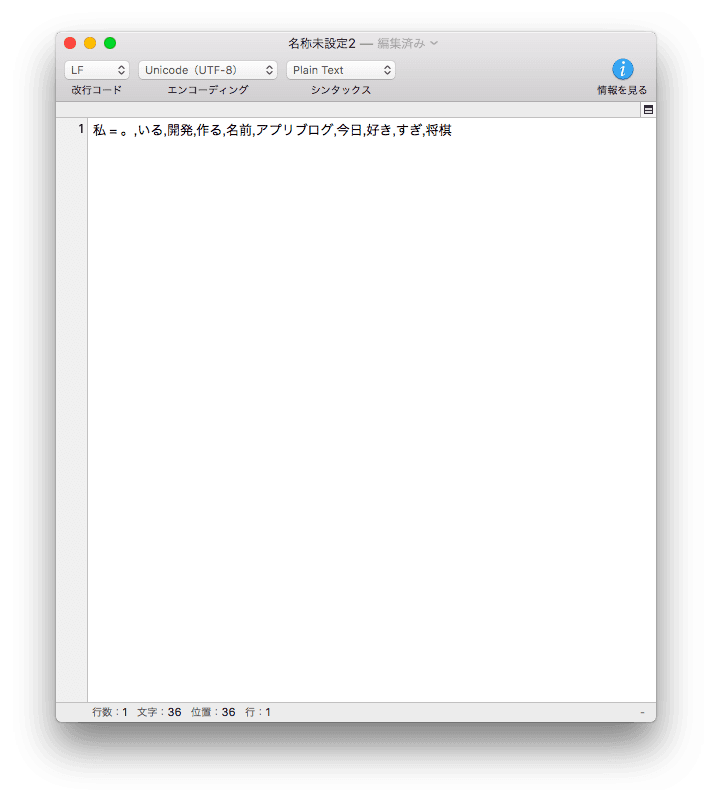
for word in ["私"]:
words = model.most_similar(positive=[word])
n = [w[0] for w in words]
print(word, "=", ",".join(n))
2では、モデル作成しておいたファイルを読み込んで、任意で決めたある単語に関する類似度を表示させます。
★word2vec.py★
# word2vec.py
# ベクトル変換ツールword2vecをインポート - 1
from gensim.models import word2vec
# 類似する語句を表示 - 2
model = word2vec.Word2Vec.load("text_2.model")
for word in ["私"]:
words = model.most_similar(positive=[word])
n = [w[0] for w in words]
print(word, "=", ",".join(n))出力結果
★用意したテキストファイル★
★形態素解析を行い、必要な品詞で分かち書きした出力ファイル★
★指定した単語の類似語句の表示結果★
また、今後もプログラミングに取り組み続けていく中で、実務に利用できる学びを身につけていかなければなりません。
実務の中のヒントを導き出してくれるテキストマイニングという技術を習得できたおすすめのPython本が以下のものになります。
・Pythonによるテキストマイニング入門
・やってみよう テキストマイニング -自由回答アンケートの分析に挑戦!-
・言語研究のためのプログラミング入門: Pythonを活用したテキスト処理
Pythonに特化した学習を進めたい人へ
筆者自身は、Pythonista(Python専門エンジニア)としてプログラミング言語Pythonを利用していますが、これには取り組む理由があります。
プログラミングの世界では、IT業界に深く関わる技術的トレンドがあります。
日夜新しい製品・サービスが開発されていく中で、需要のあるプログラミング言語を扱わなければなりません。
トレンドに合わせた学習がプログラミングにおいても重要となるため、使われることのないプログラミング言語を学習しても意味がありません。
こういった点から、トレンド・年収面・需要・将来性などを含め、プログラミング言語Pythonは学習対象としておすすめとなります。
オンラインPython学習サービス – 『PyQ™(パイキュー)』
「PyQ™」は、プログラミング初心者にも優しく、また実務的なプログラミングを段階的に学べることを目指し、開発されたオンラインPython学習サービスです。
Pythonにおける書籍の監修やPythonプロフェッショナルによるサポートもあり、内容は充実しています。
技術書1冊分(3000円相当)の価格で、1ヶ月まるまるプログラミング言語Pythonを学習することができます。
特に、、、
・プログラミングをはじめて学びたい未経験者
・本、動画、他のオンライン学習システムで学習することに挫折したプログラミング初心者
・エンジニアを目指している方(特にPythonエンジニア)
かなり充実したコンテンツと環境構築不要なため、今すぐにでも学び始めたい・学び直したい、Pythonエンジニアを目指したい人におすすめです。
| オンラインPython学習サービス「PyQ™(パイキュー)」 ※技術書1冊分の価格から始めて実務レベルのPythonが習得できます |


























