
目次
形態素解析について
この記事を読み進める前に、よりテキストマイニングの内容を理解したい方は、下記のURLにてチェックしてみてください。
形態素解析とは、自然言語の文章を意味を持つ最小の単位である「形態素」に分割し、品詞を判別する作業となります。形態素解析は機械翻訳やかな漢字変換、テキストマイニングなど、かくいう私も企業が持っているビッグデータを文書レベルで分析し、企業の今後の経営における方向性を探し出す業務や、人工知能に利用する学習データ作成で利用しています。
英語で形態素解析を行うのは、それほど難しくはありません。形態素ごとに単語を分かち書きするのが普通だからです。分かち書きとは、文章において単語ごとに区切ることです。
日本語で形態素解析を行うのは、それなりの工夫が必要となります。代表的な手法としては文法による方法と確率的言語モデルを用いる方法の二種類があります。最近では、後者の確率的言語モデルを利用した形態素解析が多く、精度も高くなってきています。いずれにしても、品詞辞書や文法辞書を用いて辞書に照らし合わせながら形態素解析を行います。
代表的な形態素解析のライブラリ
世の中には、すでに多くの形態素解析のライブラリが数多く存在し、それらはオープンソースで配布されています。
そして、多くのライブラリはPythonから利用できるようになっています。そのため、それらのライブラリを利用することで、自身で辞書を準備したり、形態素解析のアルゴリズムを実装する手間を省くことができます。
ここでは2つのライブラリを紹介します。
「MeCab」
形態素解析という言葉を身近に感じている方にはあまりにも有名な定番なツールがあります。
利用実績としても非常に多く定番ライブラリとして思い浮かべるツールが「MeCab」と呼ばれるツールです。「MeCab」はCRF(Conditional Random Fields)を用いたパラメータ推定による形態素解析エンジンです。
判別精度に加えて、実行速度が速いことも特徴です。本当に知名度が高く、様々なシーンで利用されています。Pythonでは、「MeCab」をインストールして、その後pipコマンドを利用してPython用のライブラリをインストールする必要があります。
「Janome」
次に、Python自身で記述された形態素解析エンジンの「Janome」についてです。
このライブラリの特徴としては、Pythonのみで記述されているため、MeCabなどの外部エンジンをインストールする必要がないという点があります。pipコマンドを利用すれば一発でインストールが完了します。
形態素解析に利用する辞書一式もインストールアーカイブに含まれています。辞書は、MeCabと同じものを利用していますので、同等の結果を得ることができます。
ただし、Python自身で記述されているため、形態素解析にかかる時間は、MeCabの10倍ほど遅いと言われています。そのため、速度が必要な場合はMeCab、利用の手軽さを優先するならばJanomeを選択すると良いかもしれません。
今回は、出現頻度の分析で利用するライブラリは、この「Janome」を利用して行ってみました。
出現頻度の分析
上記では、形態素解析についてとライブラリについて紹介しました。
今回は、出現頻度の分析を「Janome」ライブラリを利用してプログラムを作成していきます。
プログラムの概要
■プログラムの内容
・必要なライブラリをインポートする
・任意のデータを読み込み、形態素解析を行う
・テキストを名詞だけカウントし、出現頻度を分析する
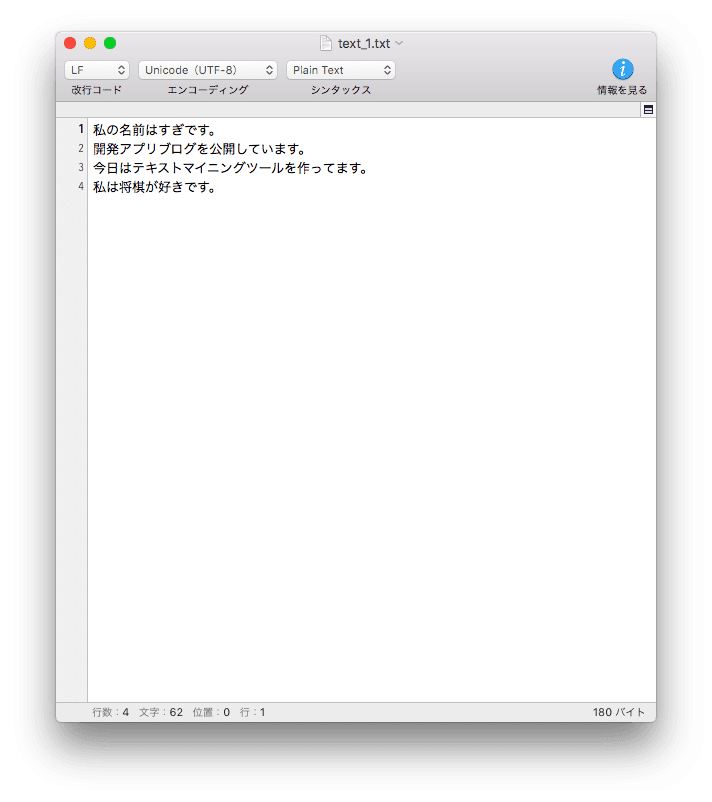
利用したデータは、text_1.txtとしてファイルを保存しています。
以下がファイル内のテキストデータになります。
# python解析器janomeをインポート - 1 from janome.tokenizer import Tokenizer # 形態素解析用オブジェクトの生成 - 2 text = Tokenizer()
1では、python解析器「Janome」をインポートします。2では、変数txtにて形態素解析用オブジェクトの生成を行います。
# txtファイルからデータの読み込み - 3
text_file = open("text_1.txt")
bindata = text_file.read()
txt = bindata
# txtから読み込んだデータを形態素解析 - 4
lines = txt.split("\r\n")
for i in lines:
print(i)
print("\n")
text_c = text.tokenize(i)
for j in text_c:
print(j)
print("\n")
3では、任意のテキストデータを読み込みます。4にて、読み込んだテキストデータを単語ごとに形態素解析します。
# テキストを一行ごとに処理 - 5
word_dic = {}
lines_1 = txt.split("\r\n")
print(lines_1)
print("\n")
for line in lines_1:
malist = text.tokenize(line)
for w in malist:
word = w.surface
ps = w.part_of_speech # 品詞 - 6
if ps.find("名詞") < 0: continue # 名詞だけをカウント - 7
if not word in word_dic:
word_dic[word] = 0
word_dic[word] += 1
5では、テキストを一行ごとに処理しています。forループにて形態素解析を行った行ごとに品詞の”名詞”をif文内でカウントします。
# よく使われる単語を表示 - 8
keys = sorted(word_dic.items(), key=lambda x:x[1], reverse=True)
for word, cnt in keys[:50]:
print("{0}({1}) ".format(word,cnt), end="")
8では、よく使われる単語を表示するため、forループにて処理を行っています。
実際に出力結果をみて頂けると分かりやすいと思います。
★text-mining.py★
# text-mining.py
# python解析器janomeをインポート - 1
from janome.tokenizer import Tokenizer
# 形態素解析用オブジェクトの生成 - 2
text = Tokenizer()
# txtファイルからデータの読み込み - 3
text_file = open("text_1.txt")
bindata = text_file.read()
txt = bindata
# txtから読み込んだデータを形態素解析 - 4
lines = txt.split("\r\n")
for i in lines:
print(i)
print("\n")
text_c = text.tokenize(i)
for j in text_c:
print(j)
print("\n")
# テキストを一行ごとに処理 - 5
word_dic = {}
lines_1 = txt.split("\r\n")
print(lines_1)
print("\n")
for line in lines_1:
malist = text.tokenize(line)
for w in malist:
word = w.surface
ps = w.part_of_speech # 品詞 - 6
if ps.find("名詞") < 0: continue # 名詞だけをカウント - 7
if not word in word_dic:
word_dic[word] = 0
word_dic[word] += 1
# よく使われる単語を表示 - 8
keys = sorted(word_dic.items(), key=lambda x:x[1], reverse=True)
for word, cnt in keys[:50]:
print("{0}({1}) ".format(word,cnt), end="")
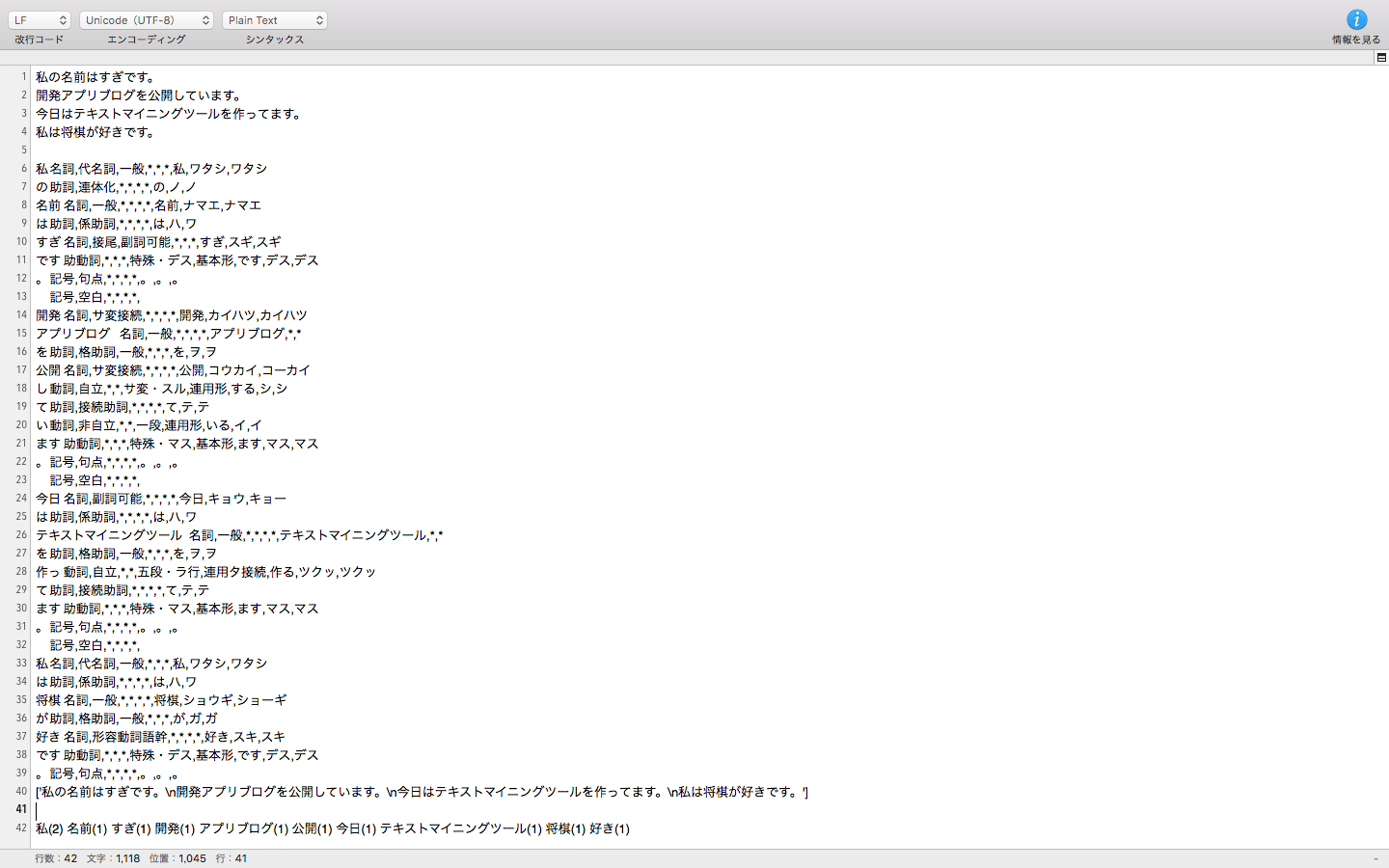
出力結果
上記に記載したプログラムを実行した出力結果をここに表示しておくので、参考にしてみてください。
ここまでで今回の形態素解析についてのプログラムは完了です。
また、今後もプログラミングに取り組み続けていく中で、実務に利用できる学びを身につけていかなければなりません。
実務の中のヒントを導き出してくれるテキストマイニングという技術を習得できたおすすめのPython本が以下のものになります。
・Pythonによるテキストマイニング入門
・やってみよう テキストマイニング -自由回答アンケートの分析に挑戦!-
・言語研究のためのプログラミング入門: Pythonを活用したテキスト処理
プログラミング学習で作りたいものがない場合
独学・未経験から始める人も少なくないので、プログラミング学習の継続や学習を続けたスキルアップにはそれなりのハードルが設けられています。
また、プログラミング学習においても、学習者によってはすでに学習対象とするプログラミング言語や狙っている分野が存在するかもしれません。
そのため、費用を抑えて効率的にピンポイント学習で取り組みたいと考える人も少なくありません。
また、プログラミング学習において目的を持って取り組むことは大切ですが、『何を作ればいいかわからない。。』といったスタートの切り方で悩む人もいると思います。
そういったプログラミング学習の指標となる取り組み方について詳細に記載したまとめ記事がありますので、そちらも参照して頂けると幸いです。

Pythonに特化した学習を進めたい人へ
筆者自身は、Pythonista(Python専門エンジニア)としてプログラミング言語Pythonを利用していますが、これには取り組む理由があります。
プログラミングの世界では、IT業界に深く関わる技術的トレンドがあります。
日夜新しい製品・サービスが開発されていく中で、需要のあるプログラミング言語を扱わなければなりません。
トレンドに合わせた学習がプログラミングにおいても重要となるため、使われることのないプログラミング言語を学習しても意味がありません。
こういった点から、トレンド・年収面・需要・将来性などを含め、プログラミング言語Pythonは学習対象としておすすめとなります。
オンラインPython学習サービス – 『PyQ™(パイキュー)』
「PyQ™」は、プログラミング初心者にも優しく、また実務的なプログラミングを段階的に学べることを目指し、開発されたオンラインPython学習サービスです。
Pythonにおける書籍の監修やPythonプロフェッショナルによるサポートもあり、内容は充実しています。
技術書1冊分(3000円相当)の価格で、1ヶ月まるまるプログラミング言語Pythonを学習することができます。
特に、、、
・プログラミングをはじめて学びたい未経験者
・本、動画、他のオンライン学習システムで学習することに挫折したプログラミング初心者
・エンジニアを目指している方(特にPythonエンジニア)
かなり充実したコンテンツと環境構築不要なため、今すぐにでも学び始めたい・学び直したい、Pythonエンジニアを目指したい人におすすめです。
| オンラインPython学習サービス「PyQ™(パイキュー)」 ※技術書1冊分の価格から始めて実務レベルのPythonが習得できます |


























