
データを整形する
今回作成するプログラムは、pythonによる機械学習にてこのブログのある月のアクセス数を取り込み、近似モデルを構築することを目的とします。
まずはじめに用意するのは、機械学習に必要なデータです。
データファイルは”tsv”ファイルとします。
tsvファイルとは、データの各項目間が「タブ」で区切られているファイルのことです。
データの中身はこんな感じです。
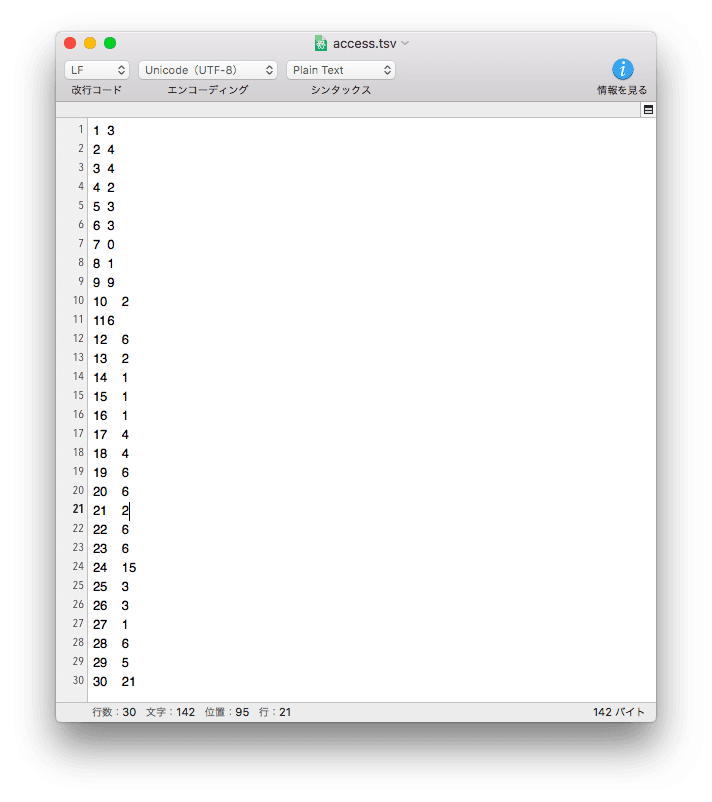
左の項目は日単位を表しており、右の項目はアクセス件数を表しています。(アクセス件数が少ないのは悩みどころです笑)
このデータを読み込んでみて、プログラムとして処理しやすいように整形していきます。
以下のようなコードを記載します。
# scipy, csv(tsvにも適用), matplotlibをインポート - 1
import scipy as sp
import csv
import matplotlib.pyplot as plt
# データファイルの読み込み - 2
data = sp.genfromtxt("access.tsv", delimiter="\t")
x = data[:,0]
y = data[:,1]
x = x[~sp.isnan(y)]
y = y[~sp.isnan(y)]
# 前処理とデータ整形の確認 - 3
print(data[:5])
print(data.shape)
print(x)
print(y)
◇ コメント 1
必要なライブラリとして、scipy, csv, matplotlibをインポートします。
SciPyは、多くのアルゴリズムを提供しています。今回はデータの読み込みと整形に利用します。
csvは、tsvファイルにも適用されるため利用しています。
matplotlibは、Pythonを使用してグラフを作成することに関してとても便利な高機能ライブラリのため利用しています。
◇ コメント 2
sp.genfromtxt()では、任意のデータファイルと区切り”タブ”を指定して読み込みを行います。
変数x, yは、取得したデータを次元ごとに分割し、それぞれの変数に格納しています。
さらに、利用するデータの中に、不適切な値を取り除くためにisnan()関数にて要素を取り出します。
ただ、今回のtsvファイルには不適切な値は存在しないため、利用しなくていいのですが、このプログラムを参考にする方もいるかもしれないので、不適切な値も考慮したプログラムとします。
◇ コメント 3
ここでは、整形したデータがどのような状態となっているか確認しているだけなので、特に説明は必要ないと思います。
配列の要素として、値が取り出せていれば問題ないと思います。
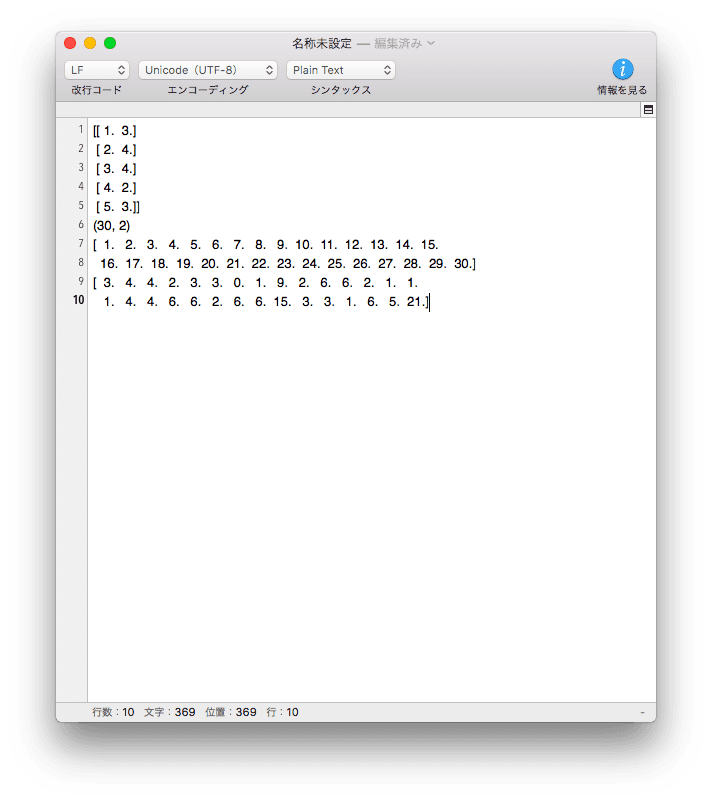
★出力結果★
近似モデルを構築する
次に、近似モデルの構築についてです。今回利用しているデータを眺めると、日が経つにつれてアクセス件数が増加していることがわかります。(少しづつ上がっていて何より笑)
ここで、やや右肩上がりの増加傾向がみて取れるので、1次式の近似モデルを構築してみます。
以下にコードを記載します。
# polyfitにてx,yと多項式の次元指定により誤差を最小とするモデル関数を取得 - 4 fp1, residuals, rank, sv, rcond = sp.polyfit(x, y, 1, full=True) # polyfitにて取得した係数をもとにモデル関数f1を作成 - 5 f1 = sp.poly1d(fp1) # f1の直線を引く - 6 fx1 = sp.linspace(0, x[-1], 1000) plt.plot(fx1, f1(fx1), linewidth=1) plt.legend(["d=%i" % f1.order], loc="upper left")
◇ コメント 4
SciPyのpolyfitは、引数に配列を渡すだけで、多項式の次元指定により誤差を最小とするモデル関数を取得できます。
傾きと切片を求めてくれるわけですね。
ただ、利用するのはfp1のみであり、引数にfull=Trueを渡すことで近似プロセスの情報を得ることができますが、fp1以外利用しません。
そのため、、、
fp1 = sp.polyfit(x, y, 1)
このコードでも構いませんし、簡略的でわかりやすいかもしれません。
◇ コメント 5
SciPyのpoly1d()関数を利用して、取得した係数を元にモデル関数f1を作成します。
◇ コメント 6
次に、f1の直線を引く用意をします。
SciPyのlinspace()にて、線形に等間隔なベクトルを作成します。0,x[-1]の範囲で1000個の点を出力させます。
そして、matplotlibのpyplotを利用して、fx1の範囲でf1関数の線を線幅1で指定し引きます。
plt.legend()にて、凡例を記載するためのコードを記載しています。
グラフに描画する
日単位が横軸(x)、アクセス数が縦軸(y)の散布図を描きます。そこに上記で求めた近似モデルの線を描きます。
以下にコードを記載します
# グラフの描画 - 7
plt.scatter(x,y)
plt.title("traffic")
plt.xlabel("Day")
plt.ylabel("access")
plt.xticks([d for d in range(31)],
['%i'%d for d in range(31)])
plt.autoscale(tight=True)
plt.grid()
plt.show()
◇ コメント 7
取り込んだデータを線と併せて描画するため、plt.scatter()を利用します。
plt.title(), plt.xlabel(), plt.ylabel(), plt.xticks(), plt.autoscale(), plt.grid(), plt.show()にて、体裁と描画を記載しています。
ここまでで近似モデルの構築プログラムの完成となります。
★access.py★
# access.py
# scipy, csv(tsvにも適用), matplotlibをインポート
import scipy as sp
import csv
import matplotlib.pyplot as plt
# データファイルの読み込み
data = sp.genfromtxt("access.tsv", delimiter="\t")
x = data[:,0]
y = data[:,1]
x = x[~sp.isnan(y)]
y = y[~sp.isnan(y)]
# 前処理とデータ整形の確認
print(data[:5])
print(data.shape)
print(x)
print(y)
# polyfitにてx,yと多項式の次元指定により誤差を最小とするモデル関数を取得
#fp1, residuals, rank, sv, rcond = sp.polyfit(x, y, 1, full=True)
fp1 = sp.polyfit(x, y, 1)
# polyfitにて取得した係数をもとにモデル関数f1を作成
f1 = sp.poly1d(fp1)
# f1の直線を引く
fx1 = sp.linspace(0, x[-1], 1000)
plt.plot(fx1, f1(fx1), linewidth=1)
plt.legend(["d=%i" % f1.order], loc="upper left")
# グラフの描画
plt.scatter(x,y)
plt.title("traffic")
plt.xlabel("Day")
plt.ylabel("access")
plt.xticks([d for d in range(31)],
['%i'%d for d in range(31)])
plt.autoscale(tight=True)
plt.grid()
plt.show()
より良い近似モデルを構築する
上記で作成したプログラムを実行してみます。
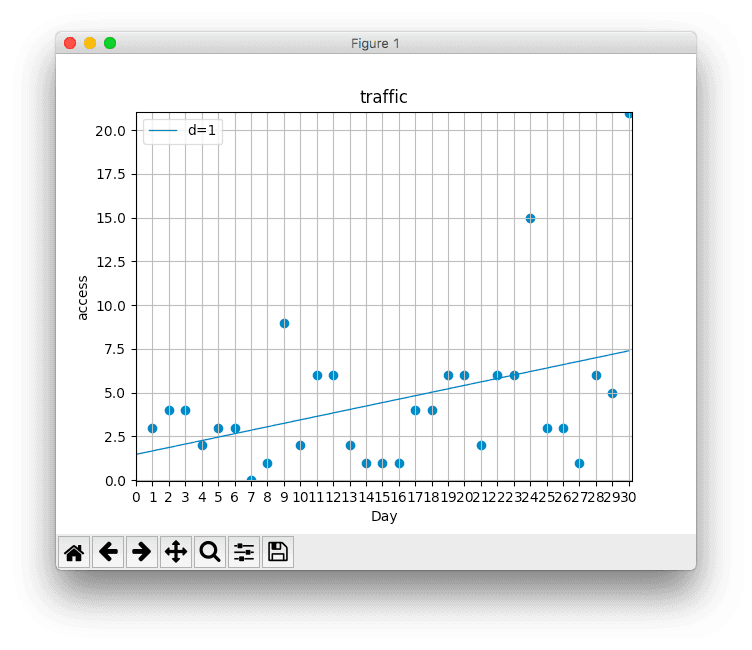
画像を眺めていると、正しいモデルとしては採用できないとわかりますよね。
そこで、次元数を増やして、より良い近似モデルを構築していきます。
作成したプログラム内に次元数を変化させたモデルを追加していきます。
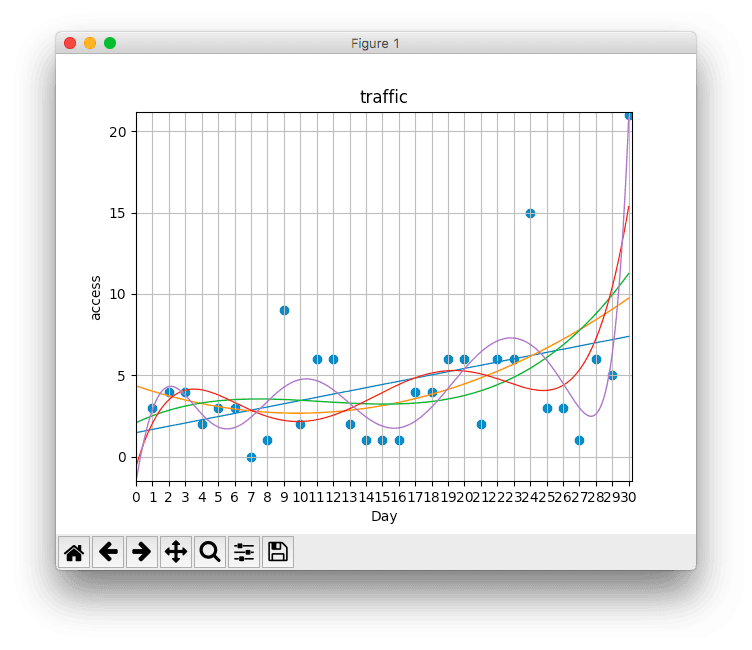
画像にて、青が1次モデル、黄が2次モデル、緑が3次モデル、赤が5次モデル、紫が10次モデルとなります。
このように、次数を増加させていくことでより良い近似モデルを構築することができました。
ここまでで、今までみてきた5つのモデルの中で、次数が低いものは明らかに単純なモデルとなっています。
元のデータがあまり利用しやすいものではありませんが、次数を増加させすぎると過学習になってしまいます。
それでは!!
実務における精度の高い成果をデータから算出したい場合に、おすすめするPython本は以下のものになります。
・Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
・すぐに使える! 業務で実践できる! Pythonによる AI・機械学習・深層学習アプリのつくり方
・直感でわかる! Excelで機械学習
機械学習や分析の分野に興味があり、pythonを学びたいと思っている方は是非こちらもどうぞ↓

























