
Pythonによるスクレイピング技術を利用することで、様々な業務効率化を実現します。
会社でのDX化(Digital Transformation)が推進される中、スクレイピングによる業務効率化が役立っています。
|
これらの悩みを解決しながら、スクレイピングの活用方法を解説します。
記事を読み終えると、スクレイピング技術の基礎知識や具体的な稼ぎ方を理解できます。
結論は、現エンジニアやノンプログラマーどちらでもスクレイピング技術を習得することで様々な業務を改善できます。
また、筆者自身クラウドソーシングサイトであるランサーズにてコンスタントに毎月10万円を稼ぎ、スクレイピング業務にて2021年6月に最高報酬額である30万円を突破しました。
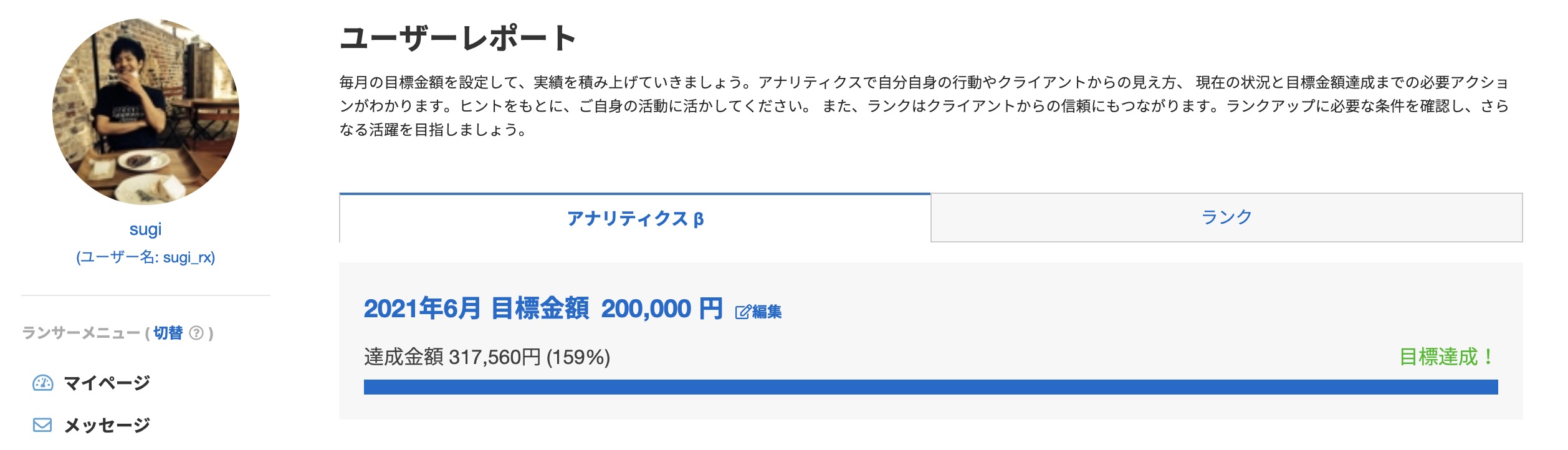
年間報酬額も100万円突破するなど、実務的なスクレイピング技術の活用方法や具体的な稼ぎ方について、一定の記事信頼を担保できると思います。
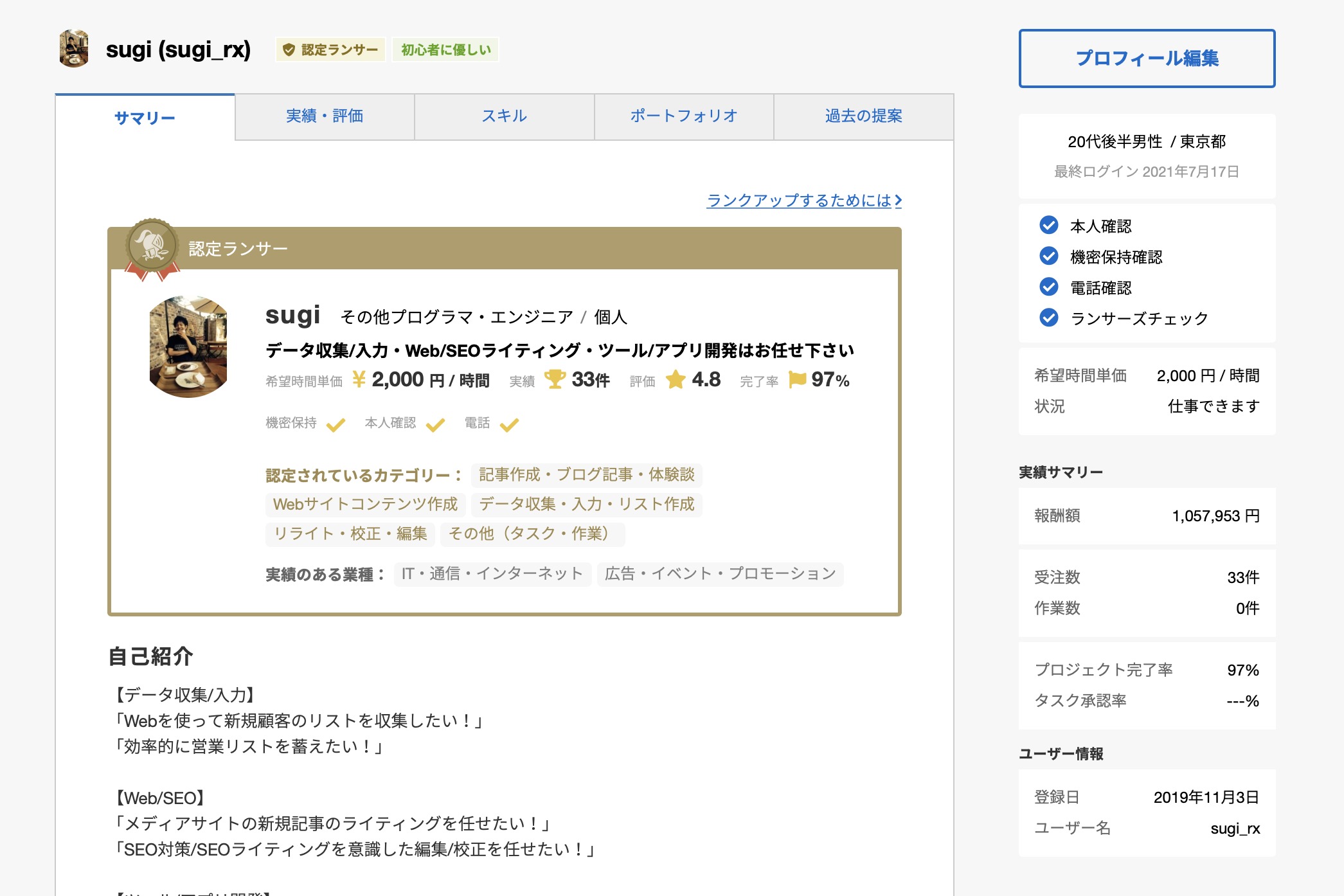
プログラミングの中でもスクレイピング技術は習得することで、副業に十分活かせる武器になると先にお伝えしておきます。
目次
スクレイピングとは何か
スクレイピングとは、特定のWebサイトにおけるページ情報を収集することです。
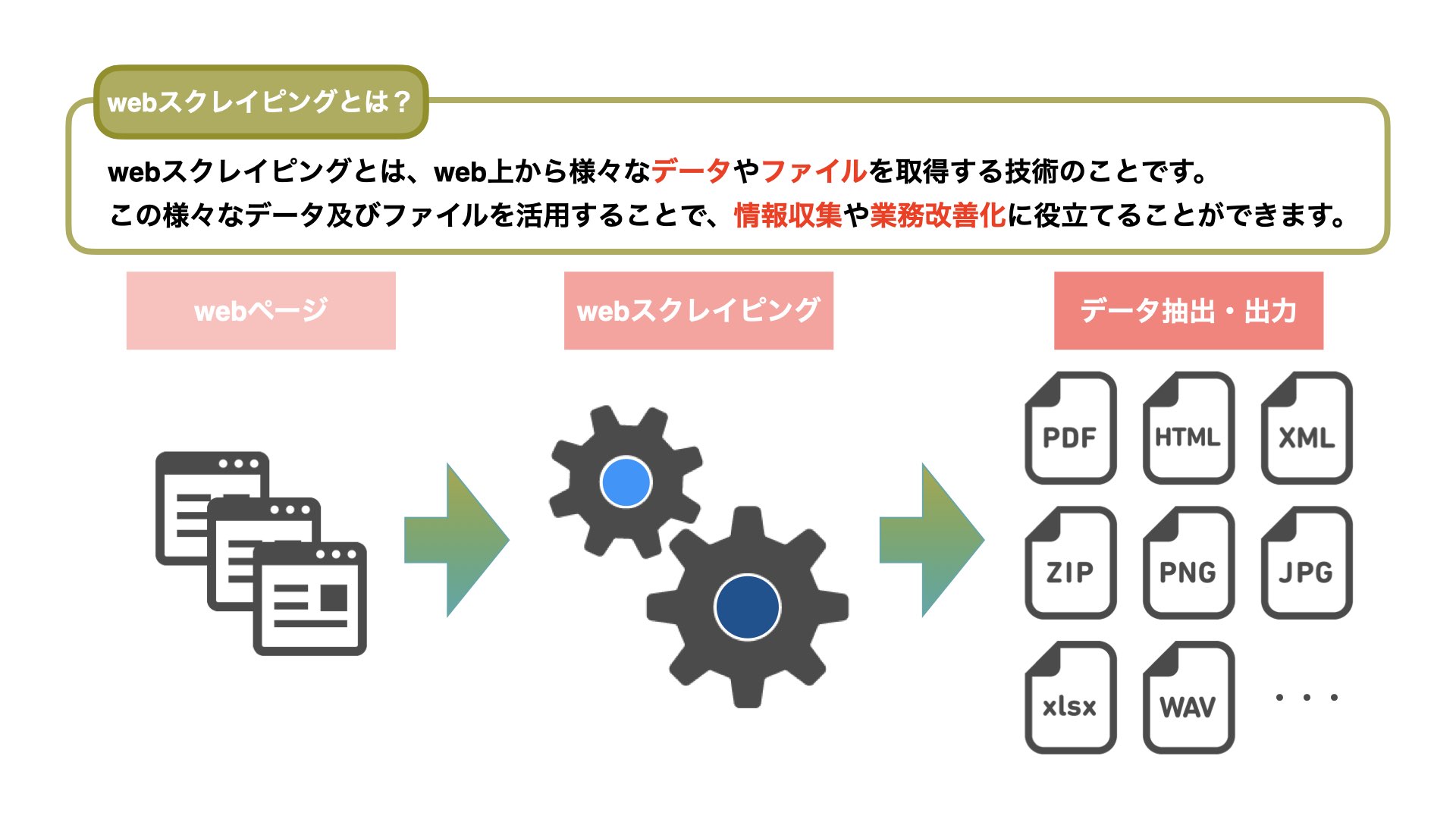
一般的に実務で利用されるスクレイピング技術は、ExcelファイルやCSVファイルに大量の収集データを保存します。
以下の画像は、就職・転職情報を提供するマイナビから取得した企業情報をCSVファイルにまとめた一部データです。

マイナビのサイトにて特定キーワードを決め、「会社名」「住所」「電話番号」などを抽出しています。
取得したいデータが複数存在すれば、pythonを利用してスクレイピングできます。
スクレイピングでできること
pythonによるスクレイピングでできることは、主に以下の2つです。
|
たった2つと感じるかもしれませんが、これらの技術習得で様々な業務効率化や稼ぐ手段に活用できます。
スクレイピング以外にも、pythonは簡単なプログラムで様々な操作が可能です。
python初心者でも実現可能なプログラムは数多くあるため、python初心者が簡単に作成できるものを知りたい人は、「【認定ランサー】Python初心者が作れるものを目的別に学習方法解説!」で解説します。

スクレイピングにおける具体的な流れ
スクレピングによるプログラムは、情報取得までの一連の流れを把握/理解する必要があります。
例えば、手作業でWebサイト情報を抽出し、ファイルにコピペする一連の操作手順を確認します。
|
上記の一連の操作を手作業で繰り返すことになります。
一つ一つの作業は5~10秒と短時間を繰り返すことになりますが、100~1000件以上の量をこなす場合に膨大な時間を要します。
また、単調な手作業となるため、人的ミスによりデータの信頼性が失われる可能性もあります。
一方で、スクレイピングによるプログラムの一連の操作手順を確認します。
|
操作手順は手作業と同じですが、これらを全て自動化することで単調な作業を効率化します。
そして、一連の操作を実現するためにスクレイピングにおいて必要な知識が3つ存在します。
スクレイピングに必要となる知識
スクレイピングに必要となる知識は、主に以下の3つです。
|
これら3つの知識が複合的に利用されてプログラムが作られます。
スクレイピングに必要となる知識を一つ一つ解説します。
スクレイピングに必要となるHTML/CSSの知識
本記事では、マイナビサイトを例に解説します。
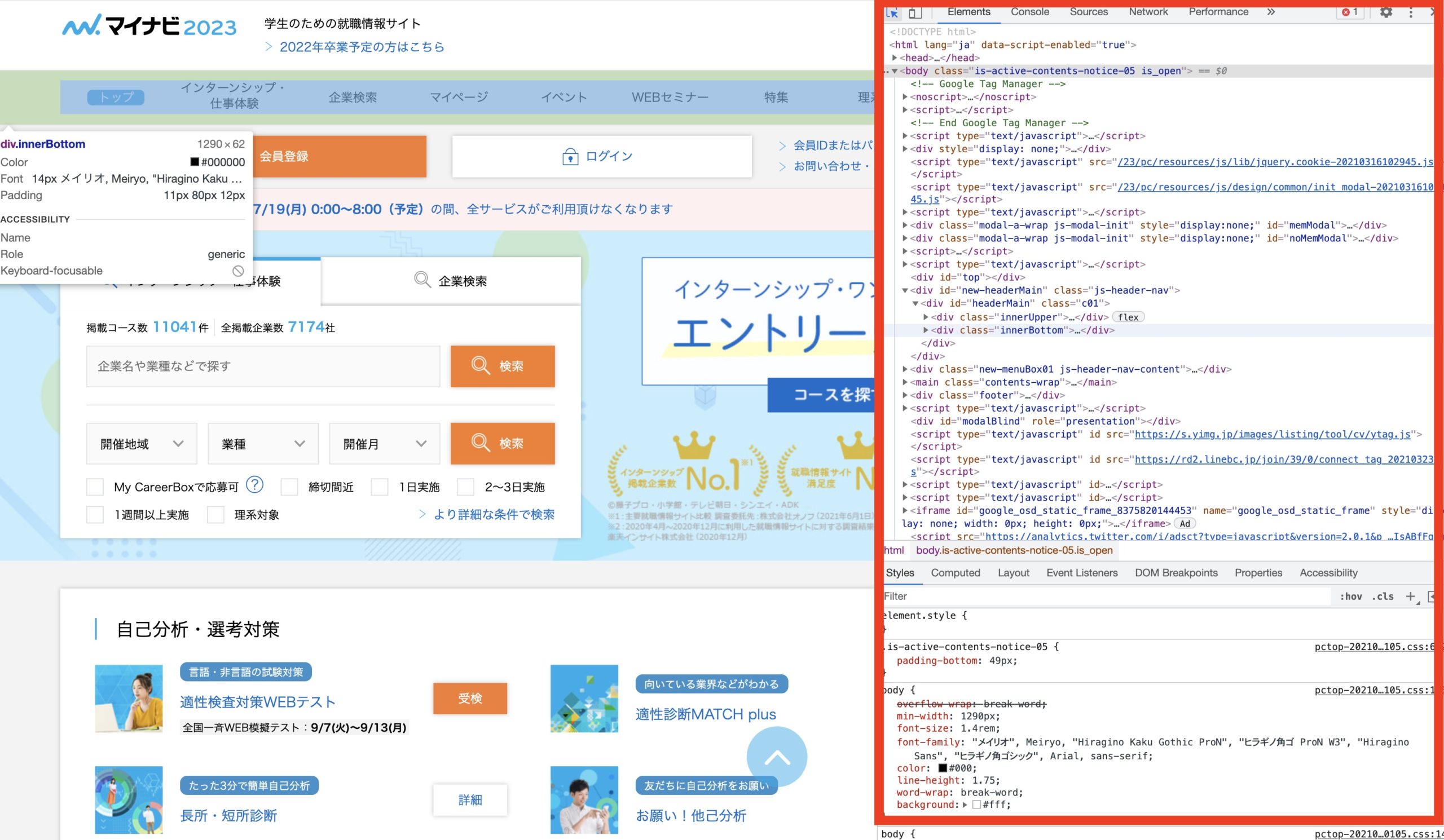
画像の赤枠で示した箇所がマイナビサイトのHTML/CSS構造になります。
WebサイトはHTML/CSSにて構成されているため、ページURLだけでなくページ内に存在する特定情報を抽出する際に活用します。
スクレイピングに必要となるライブラリの知識
ここでは、pythonによるスクレイピングで利用するライブラリをご紹介します。
スクレイピングで利用するpythonライブラリは、以下の3つです。
|
これら3つのライブラリを活用することで、スクレイピング操作を実現します。
requestsは、特定サイトのURL情報から通信を行い、ページ検出やアクセスに利用するライブラリです。
BeautifulSoupは、HTML解析やページ内の特定情報の抽出に利用するライブラリです。
Seleniumは、URL情報だけでは操作できないブラウザ特有の操作(ログイン機能を持ったサイトなど)を再現しながら自動化するためのライブラリです。
特に、SeleniumはSNSなどのWebサイトで効果的に利用できます。
特定のWebサイトが既に決められている人であれば、3つのライブラリを駆使してすぐにでもスクレイピングを実行できると思います。
スクレイピングに必要となるファイル操作の知識
基本的に、スクレイピングで利用されるファイル形式は以下の2つです。
|
特に、案件受注して納品するファイルはCSVファイルがほとんどです。
実践的なスクレイピングプログラムによる稼ぎ方
ここからは、筆者がスクレイピングプログラムでどのように稼いでるか解説します。
個人的な見解ですが、無料・有料ともにスクレイピングプログラムを提供しているサイトは、直接的に収入へ直結しないサンプルコードが多いです。
筆者の考え方として、実務で利用されて金額が発生する有用なスクレイピングコードは、実際の案件から作成する必要があります。
そのため、スクレイピングを理解してプログラム実装できても、誰かに利用されるコードでなければ価値が生まれにくいと思います。
だからこそ実務である案件から実用的なスクレイピングコードを作成することで活用できます。
スクレイピングプログラムで稼ぐために確認するべきサイトは、以下の2つです。
|
やはり、日本で案件数が1,2番に多いクラウドソーシングサイトを活用することをおすすめします。
今後、プログラミング副業やフリーランスエンジニアとして活躍したいと考える人は、アカウント登録後に案件確認すると良いです。
キーワードとして「スクレイピング」「リスト作成」などで検索すると、スクレイピング案件が毎日確認できます。

実際にランサーズにて検索すると、直近でも数万円の案件として発注されています。
また、新卒採用を行う企業の求人サイトなどがスクレイピング対象となるため、リクナビやマイナビといったサイトのスクレイピングプログラムは実用的です。
他にも、Instagram・Twitter・YouTubeのアカウントリスト作成、クライアントが定めた特定サイトの企業情報の営業リスト作成があります。
副業あるいはフリーランスエンジニアとしての活動方法や筆者が実際に取り組んだ具体的な案件などを知りたい人は、「【副業】プログラミング言語学習から稼げる案件を認定ランサーが伝授!」で解説します。

pythonにおけるスクレイピングのサンプルコード
上記の解説で紹介した案件内容を元に作成したスクレイピングのサンプルコードになります。
スクレイピングの一連の流れは以下です。
|
具体的な操作と利用したキーワード等を含めた内容も画像で解説しておきます。

以下のサンプルコードで実行することができます。
import time
from datetime import timedelta
from datetime import datetime as dt
import requests, bs4
from bs4 import BeautifulSoup
from selenium import webdriver
import traceback
import os
import csv
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
#chromedriverの設定
options = Options()
#options.add_argument('--headless')
driver = webdriver.Chrome(r"driverのパス入力", chrome_options=options)
#キーワード入力
search_word = input("業種キーワード=")
# 作成日のフォルダとファイル作成
today = dt.now()
tstr = today.strftime('%Y-%m-%d')
if os.path.exists(tstr) == False:
os.mkdir(tstr)
#csvファイル生成
with open(os.path.join(tstr, search_word + '.csv'),'w',newline='',encoding='utf8') as outcsv:
csvwriter = csv.writer(outcsv)
csvwriter.writerow(['会社名','住所','電話番号','メールアドレス'])
#マイナビ
url = 'https://job.mynavi.jp/22/pc/corpinfo/searchCorpListByGenCond/index?actionMode=searchFw&srchWord=' + search_word + '&q=' + search_word + '&SC=corp'
driver.get(url)
#企業詳細url格納リスト
com_urls = []
#企業の詳細urlの取得
while True:
i = 0
count = 0
error_flag = 0
wait = WebDriverWait(driver, 10)
com_list = wait.until(EC.visibility_of_all_elements_located((By.CLASS_NAME, 'boxSearchresultEach')))
count = len(com_list)
for lists in com_list:
com_url = lists.find_element_by_tag_name("a").get_attribute("href")
com_urls.append(com_url)
i = i + 1
try:
if i == count:
next_page = driver.find_element_by_xpath('//*[@id="upperNextPage"]').click()
time.sleep(3)
except:
traceback.print_exc()
error_flag = 1
if error_flag == 1:
break
driver.close()
for line in com_urls:
#レスポンスの確認
res = requests.get(line)
#解析
soup = bs4.BeautifulSoup(res.text, "html.parser")
try:
#企業の詳細リンクの取得
name = soup.select_one("#companyHead > div.heading1 > div > div > div.heading1-inner-left > h1").text
address = soup.select_one("#corpDescDtoListDescText50").text
number = soup.select_one("#corpDescDtoListDescText220").text
mail = soup.select_one("#corpDescDtoListDescText130").text
print(name,address,number,mail)
print('------------------------------------------------')
#csvファイルへの書き込み
with open(os.path.join(tstr, search_word + '.csv'),'a',newline='',encoding='utf8') as outcsv:
csvwriter = csv.writer(outcsv)
csvwriter.writerow([name, address, number, mail])
except:
traceback.print_exc()
print("next")スクレイピング案件への考え方や作成までの流れを知りたい人は「【python】Selenium&BeautifulSoup&requestsによるスクレイピング:サンプルコードあり」で解説します。

pythonによるスクレイピングサンプルコードの実行結果
以下の画像がサンプルコードの実行結果で得られたCSVファイルになります。
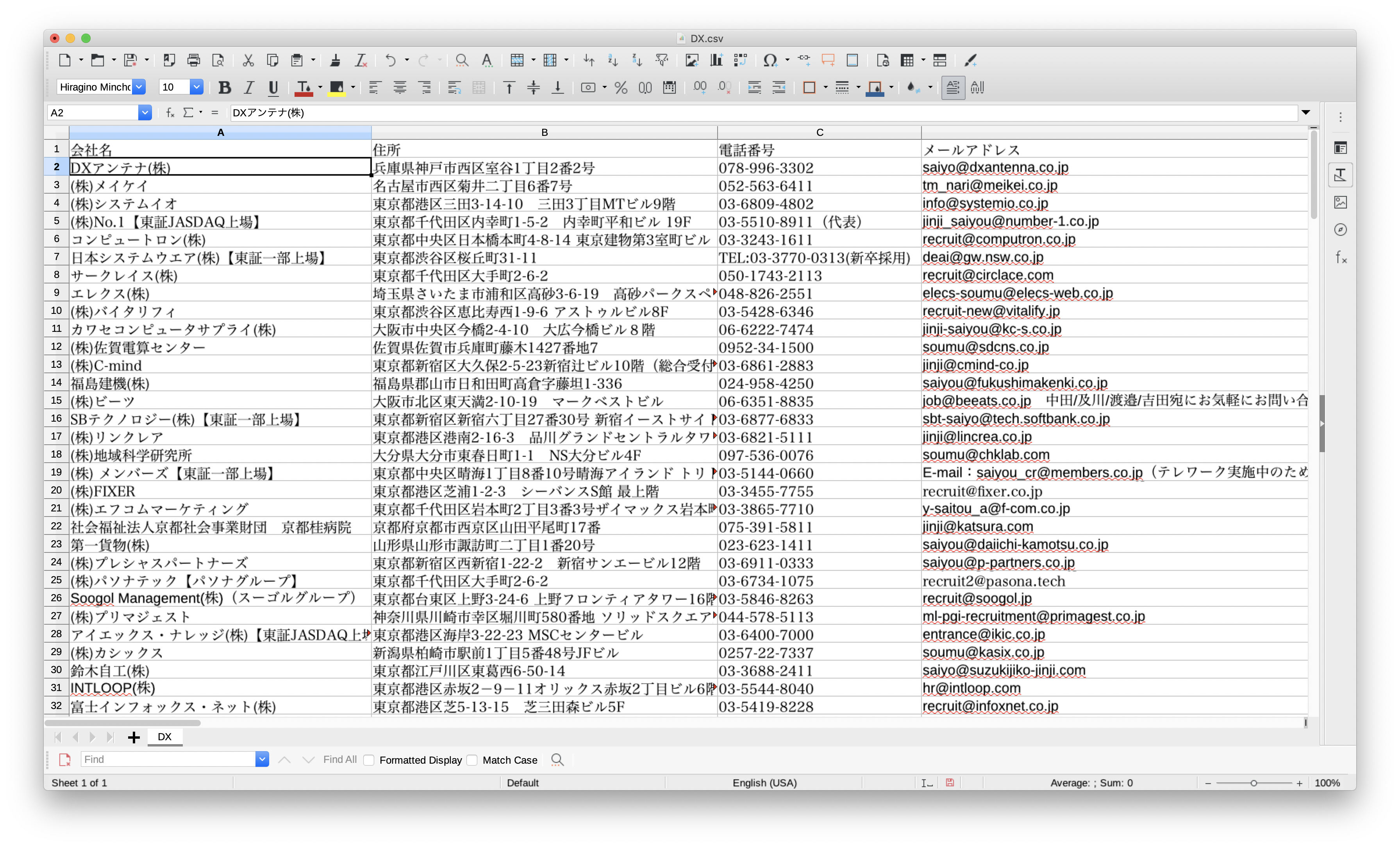
サンプルコードでは、会社名・住所・電話番号・メールアドレスの4つのデータが満たされているデータのみCSVファイルに出力されます。
そのため、キーワード”DX”にて取得できた企業データは、合計で177件(マイナビ2022より)になりました。
まとめ
スクレイピングの主な活用方法は以下の2つです。
|
特に、繰り返し処理が必要となる単調な業務に効果的です。
スクレイピングに必要となる知識は、主に以下の3つです。
|
サンプルコードを元に様々なサイトをスクレイピングしてみてください。
手っ取り早くスクレイピングプログラムで稼ぎたい人は、以下のサイトを登録しましょう。
|
今すぐにでも始められる副業になります。
また、フリーランスエンジニアを目指す人であれば、クラウドソーシングサイトを活用して実績作りするのも良いです。
pythonによるスクレイピングを習得して、実用的なプログラムを一つでも多く作成しましょう。

























