
pythonのライブラリであるSeleniumを活用することで、簡単にWebスクレイピングを実現できます。
現在多くの企業でDX化(Digital Transformation)が推進/導入されています。
|
これらの悩みを解決しながら、ブラウザ操作自動化のSeleniumを用いたWebスクレイピングコードを実装します。
最終的に、クラウドソーシングサイトなどのリスト作成案件のレベルを理解できます。
また、筆者自身クラウドソーシングサイトであるランサーズにてコンスタントに毎月10万円を稼ぎ、スクレイピング業務にて2021年6月に最高報酬額である30万円を突破しました。
年間報酬額も100万円突破するなど、実務的なスクレイピング技術の活用方法や具体的な稼ぎ方について、一定の記事信頼を担保できると思います。
プログラミングの中でもスクレイピング技術は習得することで、副業に十分活かせる武器になると先にお伝えしておきます。
目次
スクレイピングとは
一言で言えば、Webページの情報を取得することができる技術の事です。
普段よく見ているサイトや情報を検索を行うのは面倒ですが、スクレイピングの技術を使うことにより、面倒な作業をすることなく自分が欲しい情報が手に入る事ができます。
この技術は個人で実用的に使用する事はあまりありませんが、会社や個人経営されている大きな規模になると、リストの取得によく使われています。
筆者も営業会社と関わりを持つため、クライアントからキーワード検索による特定の業種の企業名・住所・サイトURL・電話番号・メールアドレスなど、多くの情報を取得して欲しいと依頼があるほどです。
1リストの値段は数円から数十円単位ですが、依頼されるリスト数が数千〜数万リストとなるため、納品後はそれなりにまとまった金額を頂くほどです。
スクレイピング技術を使いこなせるようになれば、フリーランスなど個人で稼ぐ時にとても貴重な人材となれますので、是非この機会にマスターしてしまいましょう。
Pythonでのスクレイピングでは大きく分けて3つのライブラリを使用したやり方が主流となっています。
|
特に、requests&BeautifulSoupで解決できないブラウザ操作を実装できるSeleniumは重宝されます。
requests&BeautifulSoup&Seleniumによる特定サイトのスクレイピング方法を知りたい人は「【python】Selenium&BeautifulSoup&requestsによるスクレイピング:サンプルコードあり」で解説します。

requests
requestsは、特定サイトのURL情報から通信を行い、ページ検出やアクセスに利用するライブラリです。
主にWEBスクレイピングでHTMLやXMLファイルからデータを取得するのに使われます。
requestsによるデータ取得はスクレイピングにおいて欠かせません。
Beautifulsoup
BeautifulSoupモジュールは、pythonのライブラリの一つでスクレイピングに特化した機能を備えています。
本来、Webページは複雑な構造をしていますが、こちらのライブラリを使ってWebページのデータを整形を行います。
こちらのライブラリはスクレイピングをしやすいような処理をしてくれます。
Selenium
Seleniumはブラウザに表示される要素を操作し、取得してどういう状態になっているかをテストできます。
元々Seleniumという技術はスクレイピングとしての活用ではなく、ブラウザに表示される挙動確認のために使われていました。
なので、Beautifulsoupに比べて使いやすさには劣りますが、動的にブラウザの挙動が確認できるので修正等の確実性が高いです。
それ以外にもブラウザを操作するので、スクリーンショットや画面のスクロールなどBeautifulsoupではできない動作ができて便利なライブラリとなっています。
スクレイピングコードが求められる案件
スクレイピングコードは、様々な案件で求められます。
また、基本的にスクレイピングコードが求められる場面は以下のタイミングです。
|
スクレイピングが情報収集を目的とするため、特定サイトが案件ごとに変化するのが一般的です。
以下の画像は、クラウドソーシングサイトであるランサーズにて発注されていた案件です。

例として取り上げましたが、クラウドワークスやランサーズで「リスト作成」案件を探せば、類似案件は大量に発注されています。
実際に受注することができて2万円ほど報酬を頂いております。
本記事で取り扱うサンプルコードは、案件完了できた成果物になります。
スクレイピングの具体的な流れや必要となる知識を詳しく知りたい人は、「【python】スクレイピングで利用する各種ライブラリと稼ぐための活用方法」で解説します。

プログラムの概要
seleniumによるGoogle mapsを使ったデータの取得方法を解説していきます。
Google側でidやclass等の変更が起きている場合があります。
その際は、デベロッパーツールを用いてid,class等の変更をお願い致します。
こちらが今回の全体のコードになります。
#seleniumとbeautifulsoupをインポート
import chromedriver_binary
from selenium import webdriver
import time
from bs4 import BeautifulSoup
import requests
import bs4
#検索蘭にキーワードを記入
keys = input("検索キーワード:")
#Google Chromeのドライバを用意
driver = webdriver.Chrome()
#Google mapsを開く
url = 'https://www.google.co.jp/maps/'
driver.get(url)
time.sleep(5)
#データ入力
id = driver.find_element_by_id("searchboxinput")
id.send_keys(keys)
time.sleep(1)
#クリック
search_button = driver.find_element_by_xpath("//*[@id='searchbox-searchbutton']")
search_button.click()
time.sleep(3)
login_button = driver.find_element_by_class_name("section-result-title")
login_button.click()
time.sleep(3)
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'html.parser')
title = soup.find(class_="GLOBAL__gm2-headline-5 section-hero-header-title-title")
link = soup.find_all(class_="section-info-text")
print("-------------------------------")
print(title.text.strip())
print(link[0].text.strip())
print(link[2].text.strip())
print(link[3].text.strip())
print("-------------------------------")今回のコードはSeleniumとrequests&Beautifulsoupを使って、スクレイピングを行っていきます。
こちらのコードの概要はGooglemapsにて地域やジャンルのデータを入力してその出力結果から一番最初のデータ(店名、住所、Webサイトのリンク、電話番号)を取得してくるプログラムになります。
このプログラムを作成するにあたって以下の内容を行います。
|
一つずつコードを使って解説していきます。
必要なモジュールのインポート
#seleniumとbeautifulsoupをインポート import chromedriver_binary from selenium import webdriver import time from bs4 import BeautifulSoup import requests import bs4
ここではimport文を使ってSelenium、Beautifulsoupをインポートしています。
さらに処理する時間を保持するtimeモジュールやパスを通すchromedriver_binaryモジュールをインポートしています。
これにより、今回のプログラムを作成する準備が整いました。
ブラウザを操作するドライバーを用意
#Google Chromeのドライバを用意 driver = webdriver.Chrome()
今回はGoogleにて提供されている、Google Chromeのブラウザを使用していきます。
なので、予めChromeを操作するためにドライバーのインストールを行ってください。
→http://chromedriver.chromium.org/downloads
ドライバーとは
Seleniumをインストールしただけではブラウザを操作することができません。
操作するためにはドライバーをインストールする必要があります。
車を操作するには運転手が必要ですよね。
車がブラウザ、運転手がドライバーと思っていただければ分かりやすいかと思います。
ドライバーをインストールする際の注意点
ドライバーをインストールする場合、ご自身が扱っているChromeと同じバージョンでインストールする必要があります。
不具合を避けるためにも、最新の状態にアップグレードしておいてください。
やり方の詳細は下記のリンクを貼っておきます。
→https://support.google.com/chrome/answer/95414?co=GENIE.Platform%3DDesktop&hl=ja
Google mapsを開く
#Google mapsを開く url = 'https://www.google.co.jp/maps/' driver.get(url) time.sleep(5)
次にGoogle mapsを開いていきます。
変数にGoogle mapsのurlを格納し、その格納した変数をドライバーを使って開いています。
ここは特に難しくありませんね。
検索欄にデータを入力して、クリック
Google mapsを開くと以下の画像が表示されるかと思います。
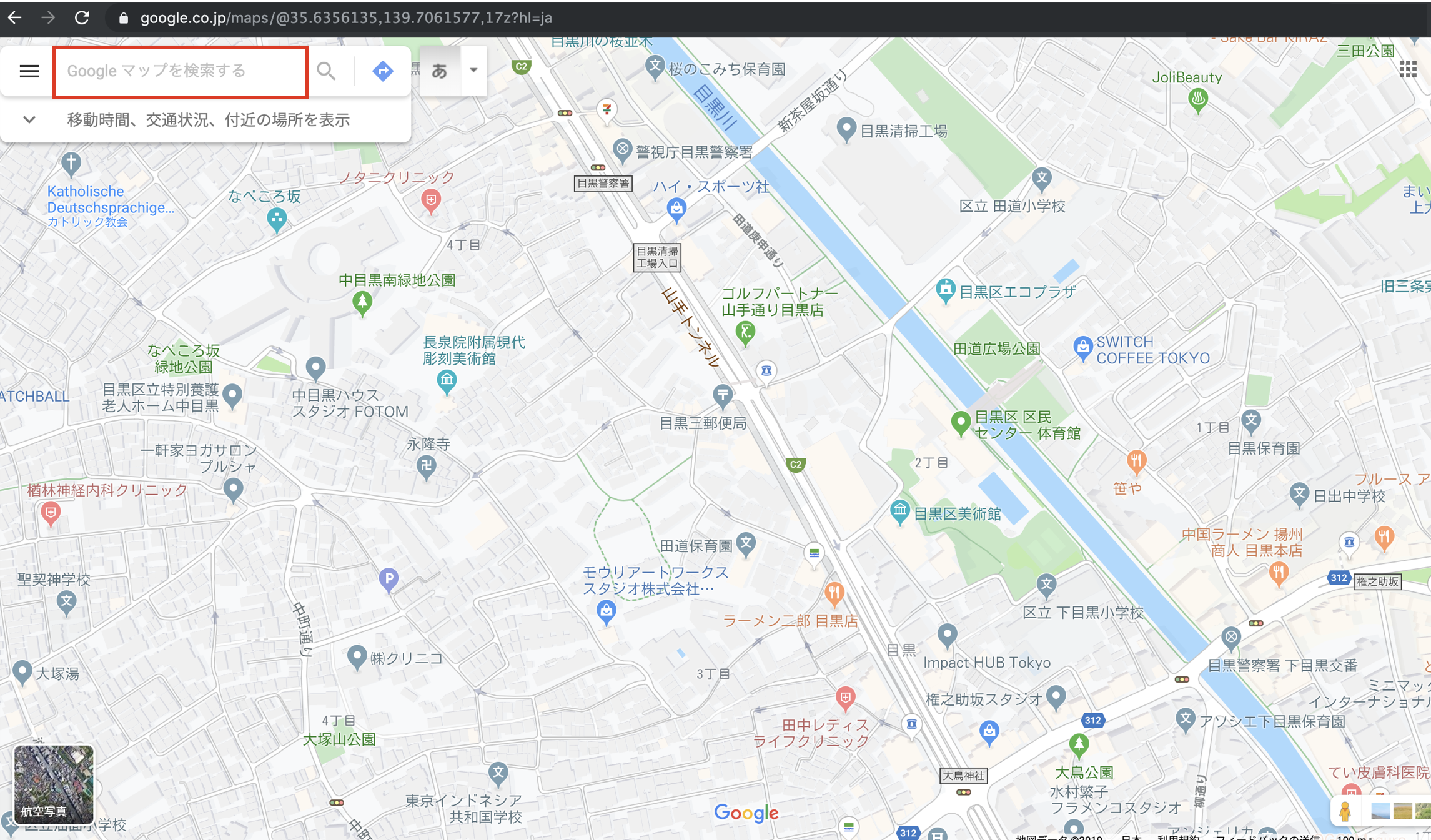
今回のコードは左上の赤枠にデータを入力して、クリックするところまで行います。
#検索蘭にキーワードを記入
keys = input("検索キーワード:")
#データ入力
id = driver.find_element_by_id("searchboxinput")
id.send_keys(keys)
time.sleep(1)
#クリック
search_button = driver.find_element_by_xpath("//*[@id='searchbox-searchbutton']")
search_button.click()
time.sleep(3)
login_button = driver.find_element_by_class_name("section-result-title")
login_button.click()
time.sleep(3)自分が取得したい地域とカフェや美容院などのジャンルを変数に格納します。今回は『渋谷 カフェ』を入力します。
それからデベロッパーツールにて検索フォームの要素を取得し、そこに先ほどの変数を入力するようにしています。
そして、クリックする要素を取得してクリックを行います。
すると、以下の画像になります。

ここでデータを取得することも可能ですが、今回取得する電話番号やWebサイトのリンクは検索結果の一覧から各個別の詳細にもう一度クリックをする必要があります。
なので、赤枠の要素を取得しクリックします。
ようやくスクレイピングをする準備が整いました。
データの整形を行い、取得したいデータを選択
#HTMLを解析
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'html.parser')
#取得したい要素を取得
title = soup.find(class_="GLOBAL__gm2-headline-5 section-hero-header-title-title")
link = soup.find_all(class_="section-info-text")
#出力
print("-------------------------------")
print(title.text.strip())
print(link[0].text.strip())
print(link[2].text.strip())
print(link[3].text.strip())
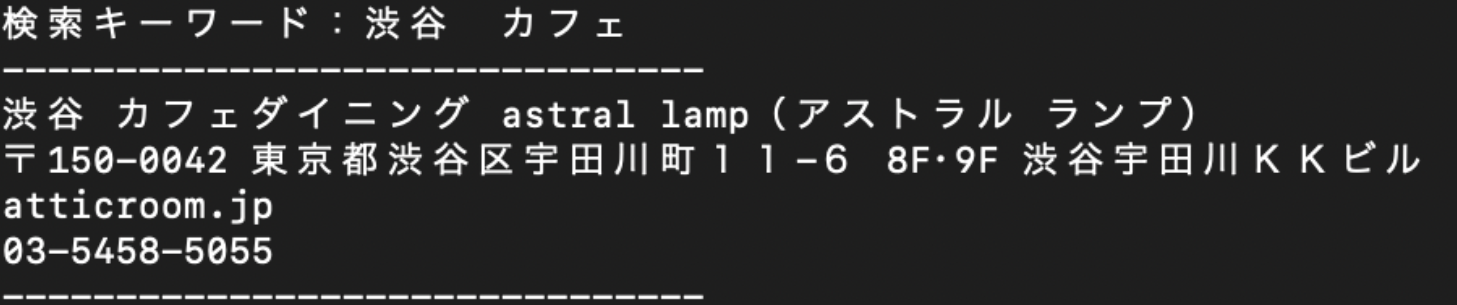
print("-------------------------------")最後にスクレイピングを行います。
このままSeleniumにてデータを取得することも可能ですが、綺麗にデータを取得する際にはrequests&Beautifulsoupがオススメですので、今回はこのPythonライブラリを使用してスクレイピングしていきます。
※今回はGoogle mapsのデータ取得のために画面遷移が多く存在したので、Seleniumも使用しましたが、本来スクレイピングする際には基本的にrequests&Beautifulsoupで完結します。
先ほど詳細ページに画面遷移したことにより、以下のように表示されているかと思います。
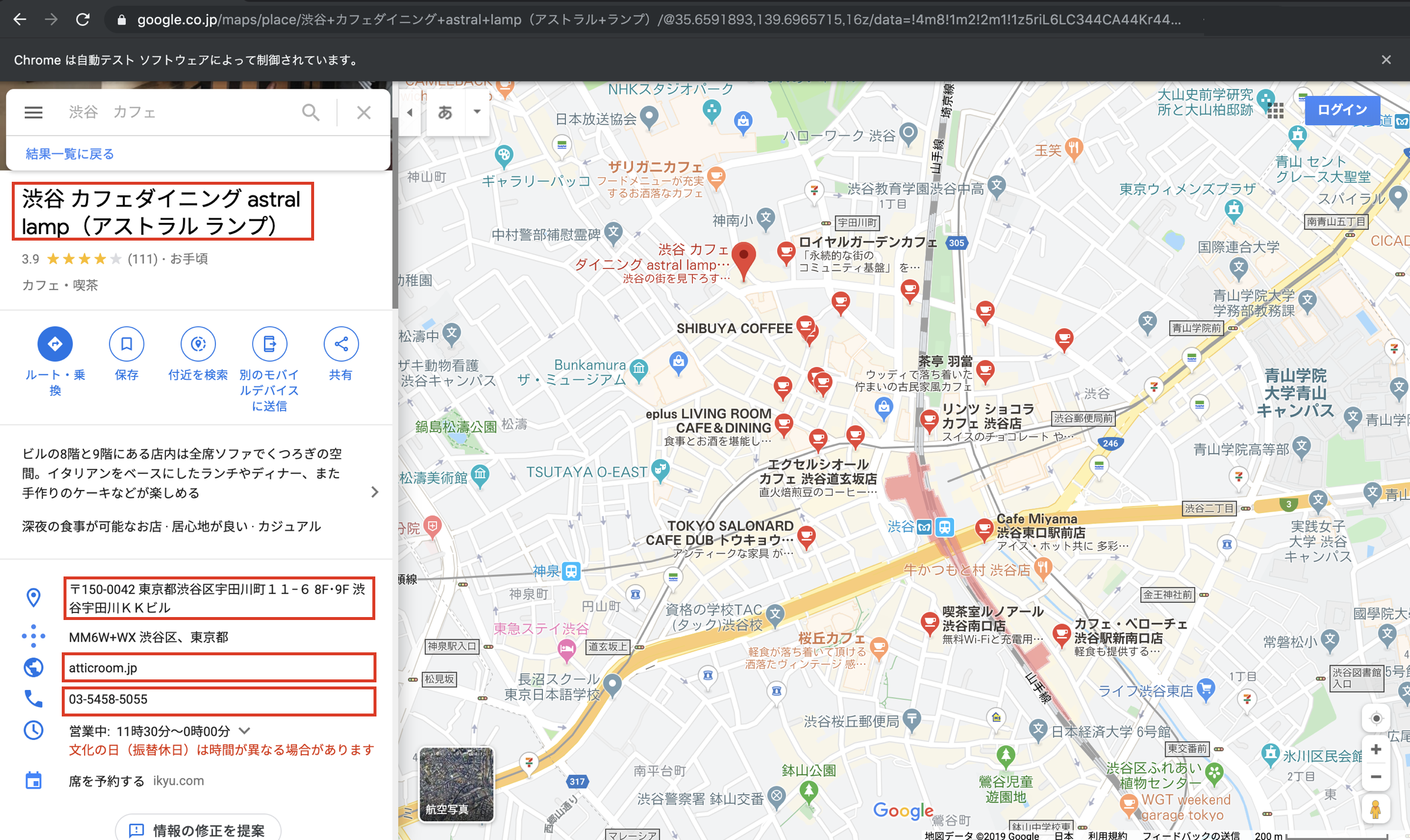
今回は図の赤枠が今回データを取得する要素となります。
ここで、PythonライブラリBeautifulsoupを使ってHTMLのデータを整形していきます。
整形したデータの中から自分が取得したいデータが存在する要素を選択肢し、出力を行います。
そのまま取得した要素を出力すると、class名なども表示されてしまうため、.textにてHTML要素内の文字のみを出力するようにしています。
ターミナルには以下のように出力されていると思います。
また、今後もプログラミングに取り組み続けていく中で、実務に利用できる学びを身につけていかなければなりません。
実務に活かす際に学習として利用していたPython本が以下のものになります。
|
プログラミング学習で作りたいものがない場合
独学・未経験から始める人も少なくないので、プログラミング学習の継続や学習を続けたスキルアップにはそれなりのハードルが設けられています。
また、プログラミング学習においても、学習者によってはすでに学習対象とするプログラミング言語や狙っている分野が存在するかもしれません。
そのため、費用を抑えて効率的にピンポイント学習で取り組みたいと考える人も少なくありません。
また、プログラミング学習において目的を持って取り組むことは大切ですが、『何を作ればいいかわからない。。』といったスタートの切り方で悩む人もいると思います。
そういったプログラミング学習の指標となる取り組み方について詳細に記載したまとめ記事がありますので、そちらも参照して頂けると幸いです。

Pythonに特化した学習を進めたい人へ
筆者自身は、Pythonista(Python専門エンジニア)としてプログラミング言語Pythonを利用していますが、これには取り組む理由があります。
プログラミングの世界では、IT業界に深く関わる技術的トレンドがあります。
日夜新しい製品・サービスが開発されていく中で、需要のあるプログラミング言語を扱わなければなりません。
トレンドに合わせた学習がプログラミングにおいても重要となるため、使われることのないプログラミング言語を学習しても意味がありません。
こういった点から、トレンド・年収面・需要・将来性などを含め、プログラミング言語Pythonは学習対象としておすすめとなります。
オンラインPython学習サービス – 『PyQ™(パイキュー)』
「PyQ™」は、プログラミング初心者にも優しく、また実務的なプログラミングを段階的に学べることを目指し、開発されたオンラインPython学習サービスです。
Pythonにおける書籍の監修やPythonプロフェッショナルによるサポートもあり、内容は充実しています。
技術書1冊分(3000円相当)の価格で、1ヶ月まるまるプログラミング言語Pythonを学習することができます。
特に、、、
・プログラミングをはじめて学びたい未経験者
・本、動画、他のオンライン学習システムで学習することに挫折したプログラミング初心者
・エンジニアを目指している方(特にPythonエンジニア)
かなり充実したコンテンツと環境構築不要なため、今すぐにでも学び始めたい・学び直したい、Pythonエンジニアを目指したい人におすすめです。
| オンラインPython学習サービス「PyQ™(パイキュー)」 ※技術書1冊分の価格から始めて実務レベルのPythonが習得できます |

まとめ
いかがでしたでしょうか?
今回はSeleniumとrequests&Beautifulsoupを使ったスクレイピングを解説していきました。
Seleniumを使うことで様々なデータを取得できることがお分り頂けたかと思います。
Pythonを学習されている方なら是非扱って欲しいです。
サイトによってスクレイピングをしてはいけない事もありますので、そこに気を付けながら行ってみてください。
最後まで一読いただき、ありがとうございました!

























